


XI. L'unicode et Java▲
XI-A. Principes fondamentaux et vocabulaire▲
Comme vous le savez déjà, un ordinateur ne comprend que le binaire. Des 0 et des 1, représentant des nombres (entiers ou à virgule).
Le codage (binaire) des caractères (charset encoding) est la relation entre un nombre entier (point de code) et un caractère. Par exemple, le nombre 0100 0001 en base 2, ou 65 en base 10, correspond à la lettre A dans la plupart des jeux de caractères.
Un jeu de caractères rassemble un ensemble fini de caractères, dont chaque caractère est codé sur un nombre de bits, défini par l'encodage.
Le terme « binaire » est ajouté à l'expression « codage des caractères », car il est possible de coder des caractères sous une autre forme, telle que le braille ou le morse.
XI-B. Avant l'Unicode▲
Tout a commencé au cours du XIXe siècle avec le Code Baudot, mais il nous est inutile de remonter si loin. En prenant quelques raccourcis, disons que pour le monde informatique les premiers jeux de caractères furent l'EBCDIC (prononcez /ˈɛbsɨdɪk/) et l'ASCII qui doit vous être plus familier. Chaque caractère ASCII est codé sur 7 bits, permettant d'avoir 128 caractères basés sur l'alphabet anglais (ASCII signifiant American Standard Code for Information Interchange).
Or, pour tous les systèmes d'écriture utilisant d'autres caractères, il a fallu créer d'autres jeux de caractères comme les différents ISO-xxxx, KOI8, JIS-yyyy, Windows-zzzz, etc., dont la plupart codent chaque caractère sur un octet.
Mais ce n'était pas une solution idéale. Chaque application internationalisée devait gérer plusieurs jeux de caractères. Finalement, à la fin des années 80 un nouveau standard, l'Unicode, a été inventé pour pouvoir coder tous les systèmes d'écriture modernes.
XI-C. L'Unicode▲
À l'origine (dans le document nommé Unicode 88), Joe Becker (l'un des créateurs de l'Unicode avec Lee Collins et Mark Davis) considérait que 16 bits seraient amplement suffisants pour représenter tous les systèmes d'écriture modernes, et que l'Unicode n'avait pas pour but de représenter des systèmes rares et/ou obsolètes.
Or en 1996, un mécanisme de caractères de remplacement a été introduit en Unicode 2. De fait, l'Unicode n'était plus limité à 16 bits. Ceci a eu pour effet d'augmenter le répertoire Unicode (codespace - nombre de caractères qu'il est possible de représenter) à plus d'un million, permettant le codage de nombreux systèmes d'écriture anciens, tel que les hiéroglyphes égyptiens et des milliers de caractères obsolètes ou rarement utilisés, considérés originellement non nécessaires. Parmi lesquels nous retrouvons les caractères chinois et les Kanji rarement utilisés puisqu'ils sont des composants de noms propres ou de lieux.
La dernière version d'Unicode (6.2) contient un peu plus de 100 000 caractères de plus de 100 systèmes d'écriture.
Le standard est maintenu par le Consortium Unicode.
L'Unicode est utilisé pour représenter les chaînes de caractères dans la plupart des langages modernes : Java, .Net (C#, VB.Net), Go, Python3, Dart, etc.
XI-C-1. Les concepts▲
L'Unicode permet de définir 1 114 112 points de code de 0x0000 à 0x10FFFF. Généralement un point de code est noté U+xxxx où xxxx est en hexadécimal, et comporte de 4 à 6 chiffres. Par exemple, U+0041 correspond à la lettre A.
Le répertoire Unicode est divisé en 17 plans, numérotés de 0 à 16. Le premier plan (plan 0) est nommé Plan Multilingue de Base (BMP). Il contient les points de code de U+0000 à U+FFFF représentant la plupart des systèmes d'écriture modernes. Les autres plans sont nommés plans supplémentaires.
Dans chaque plan, les caractères sont alloués à des blocs - nommés - de caractères liés, par exemple Basic Latin, Latin-1 Supplement, etc. Chaque bloc est de taille variable, mais cette taille est toujours un multiple de 16. Certains systèmes d'écriture sont répartis dans plusieurs blocs.
Prenons par exemple la chaîne de caractères « Bonjour ». Elle est codée en points de code Unicode de la manière suivante :
U+0042 U+006F U+006E U+006A U+006F U+0075 U+0072.
Mais attention. L'Unicode définit un jeu de caractères, mais ne spécifie en rien l'apparence d'un caractère (police de caractères), ni comment les points de code sont stockés en mémoire (codage des caractères).
À noter que les 256 premiers points de code sont identiques à ceux du jeu de caractères ISO-8859-1 rendant la conversion des textes utilisant des caractères occidentaux presque triviale.
XI-C-2. Zone d'indirection▲
Les points de code de U+D800 à U+DBFF (1024 points de code) sont connus sous le nom de point de code de la zone haute d'indirection (lead surrogate).
Les points de code de U+DC00 à U+DFFF (1024 points de code) sont connus sous le nom de point de code de la zone basse d'indirection (trail surrogate).
Un point de code de la zone haute d'indirection suivi d'un point de code de la zone basse d'indirection constituent une paire de substitution (zone d'indirection/surrogate pair) utilisée pour représenter en UFT‑16 1 048 576 points de code n'appartenant pas au BMP (plan 0). Nous y reviendrons un peu plus loin dans cet article, lorsque nous verrons l'UTF‑16.
Les zones haute et basse d'indirection ne sont pas valides lorsqu'elles sont isolées. Ainsi, les points de code pouvant être utilisés en tant que caractères vont de U+0000 à U+D7FF et de U+E000 à U+10FFFF (soit 1 112 064 points de code).
XI-C-3. Les non-caractères▲
Un « non-caractère » est un point de code qui est réservé de manière permanente dans le standard Unicode pour un usage interne.
Il y a soixante-six non-caractères :
- les points de code entre les deux zones d'indirection : U+FDD0 à U+FDEF (32 caractères) ;
- Tous les points de code finissant par FFFE ou FFFF (les deux derniers caractères de chaque plan), comme U+FFFE, U+FFFF, U+1FFFE, U+1FFFF, U+2FFFE, U+2FFFF…, U+10FFFE, U+10FFFF (34 caractères).
L'ensemble des non-caractères est stable, et aucun nouveau non-caractère ne sera défini.
XI-C-4. Caractères à usage privé▲
Les caractères à usage privé sont des points de code dont l'interprétation n'est pas spécifiée par une norme de codage de caractères et dont l'utilisation et l'interprétation peuvent être déterminées par un accord privé entre les utilisateurs/applications.
Il y a trois zones de caractères à usage privé :
- zone à usage privé (Private Use Area) : U+E000 à U+F8FF (6400 caractères) ;
- zone à usage privé supplémentaire A (Supplementary Private Use Area-A) : U+F0000 à U+FFFFD (65 534 caractères) ;
- zone à usage privé supplémentaire B (Supplementary Private Use Area-B) : U+100000 à U+10FFFD (65 534 caractères).
XI-C-5. Points de code réservés▲
Les points de code réservés sont des points de code actuellement non attribués, mais réservés pour une normalisation future. (Roadmaps to Unicode).
XI-C-6. Glyphes et graphème▲
Un glyphe est une représentation graphique d'un caractère :
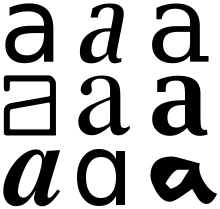
Un graphème est une unité distinctive minimale de l'écriture dans le cadre d'un système d'écriture donné. Par exemple, b et m sont des graphèmes distincts dans le système d'écriture latin, puisque par exemple en français, ils constituent des mots différents, comme bal ou mal. En revanche, a (en gras) et a (en italique) ne sont pas des graphèmes distincts, car aucun mot ne se distingue sur la base de ces deux formes différentes. Le terme graphème est souvent défini comme un caractère perçu par l'utilisateur (user-perceived character). J'imagine que certains doivent se demander où je veux en venir et quelle est l'utilité d'entrer autant dans les détails. La réponse est très simple, il s'agit d'une introduction à l'un des cauchemars de l'Unicode, et d'une manière générale de n'importe quel jeu de caractères.
À un point de code correspond un caractère, mais un caractère ne correspond pas toujours à un caractère perçu par l'utilisateur. De plus, il y a aussi des duplications.
XI-C-6-a. Un graphème et plusieurs points de code▲
Le graphème é a pour point de code U+00E9 ou la combinaison de U+0065 (e) et U+0301 ( _ ́ _ ), un accent. Il en va de même pour tous les graphèmes contenant des signes diacritiques, définis dans le bloc Unicode nommé Combining Diacritical Marks. La première forme composée d'un seul point de code est nommée forme précomposée et la seconde forme combinée. Tous les caractères français ont une forme précomposée, mais ce n'est pas le cas pour tous les systèmes d'écriture, sachant qu'un graphème peut être composé de plus de deux caractères.
XI-C-6-b. Duplication des graphèmes▲
Pour des questions de rétrocompatibilité avec d'anciens jeux de caractères, ainsi que pour garder une certaine indépendance des blocs, des graphèmes ont été dupliqués.
Le graphème μ est présent dans les blocs Greek sous le nom GREEK SMALL LETTER MU - et a pour point de code U+03BC - et Latin-1 Supplement sous le nom MICRO SIGN avec pour point de code U+00B5.
Mais ce n'est qu'un exemple, il y a de nombreux autres cas.
Que ce soit la duplication des graphèmes, la possibilité de représenter un même graphème en un ou plusieurs points de code, il y a un véritable impact dans :
- l'égalité de deux caractères et donc de deux chaînes de caractères ;
- le tri de plusieurs caractères et donc de plusieurs chaînes de caractères ;
- le comptage du nombre de caractères dans une chaîne de caractères.
XI-C-6-c. Ligatures▲
Contrairement à ce que l'on pourrait penser, le cas suivant ne pose aucun problème. Dans le mot cœur, œ est un graphème (résultat de la ligature des lettres o et e) et son point de code est U+0153.
Les ligatures, tout comme les diagraphes n'étant que des représentations particulières de deux glyphes, ils ne sont pas - toujours - assignés à un point de code (les ligatures et diagraphes assignés à un point de code, l'ont été pour des raisons de rétrocompatibilité). La tâche de les afficher correctement revient aux polices de caractères.
XI-D. Codage des caractères▲
L'Unicode définit deux méthodes de codage des caractères : l'UTF (Unicode Transformation Format) et l'UCS (Universal Character Set). Le nombre suivant l'acronyme correspondant, pour l'UTF au nombre de bits par unité de code et pour l'UCS au nombre d'octets par unité de code. L'unité de code est la combinaison minimale de bits pouvant représenter une unité de texte codé pour un traitement ou un échange. Le standard Unicode utilise des unités de code de 8 bits pour l'UTF-8, 16 pour l'UTF-16 et 32 pour UTF-32. L'UTF-8 et l'UTF-16 sont probablement les formes de codage des caractères les plus utilisées. L'UCS-2 est un sous-ensemble de l'UTF-16 aujourd'hui obsolète, et l'UCS-4 et l'UTF-32 sont fonctionnellement équivalents.
XI-D-1. UTF-32▲
En UTF-32 (et UCS-4), une unité de code de 32 bits permet de représenter sans aucune transformation un point de code (même si le boutisme, qui varie selon les différentes plates-formes, affecte la façon dont la valeur de code se manifeste dans une séquence d'octets). Dans les autres codages, chaque point de code peut être représenté par un nombre variable d'unités de code. UTF-32 est principalement utilisé comme représentation interne du texte dans les programmes (par opposition au texte stocké ou transmis), notamment des éditeurs de texte.
XI-D-2. UTF-16▲
En UTF-16 (et UCS-2) les points de codes du BMP sont codés sur 2 octets, sans aucune transformation.
En revanche, pour les plans supplémentaires l'UCS-2 n'est pas adapté. L'UTF-16, quant à lui, code les points de codes par paires d'unités de code de 16 bits, appelées paires de substitution codées sur 4 octets. Le codage est effectué de la manière suivante :
- On soustrait 0x10000 au point de code. Le résultat est un nombre de 20 bits, compris entre 0 et 0xFFFFF (résultat de la soustraction 0x10FFFF - 0x10000) ;
- On ajoute 0xD800 aux dix bits supérieurs (un nombre compris entre 0 et 0x3FF). Le résultat constitue la première unité de code (comprise entre 0xD800 et 0xDBFF), appelée aussi zone haute d'indirection ;
- On ajoute 0xDC00 aux dix bits inférieurs (un nombre compris entre 0 et 0x3FF). Le résultat constitue la seconde unité de code (comprise entre 0xDC00 et 0xDFFF), appelée aussi zone basse d'indirection.
Pour rappel, les zones haute et basse d'indirection ne sont pas valides lorsqu'elles sont isolées. Par conséquent, il ne peut y avoir d'erreur d'interprétation entre un point de code codé sur 2 octets et un autre codé sur 4 octets.
Exemple avec le point de code U+64321.
- Commençons par soustraire 0x10000 au point de code 0x64321 - 0x10000 = 0x54321 = 0101 0100 0011 0010 0001
- Passons ensuite à la première unité de code : 0x54321 >> 10 = 01 0101 0000 = 0x0150
0x0150 + 0xD800 = 0xD950 - Et terminons par la seconde unité de code 0x54321 & 0x3FF = 11 0010 0001 = 0x0321
0x0321 + 0xDC00 = 0xDF21
U+64321 appartenant à un plan supplémentaire (puisque supérieur à U+FFFF), en mémoire il est codé sur les 4 octets suivants : D9 50 DF 21.
XI-D-3. UTF-8▲
En UTF-8, un point de code est codé sur un, deux, trois ou quatre octets.
Le codage est effectué de la manière suivante :
|
Interval |
Octet 1 |
Octet 2 |
Octet 3 |
Octet 4 |
|
U+0000 - U+007F |
0xxxxxxx |
|||
|
U+0080 - U+07FF |
110xxxxx |
10xxxxxx |
||
|
U+0800 - U+FFFF |
1110xxxx |
10xxxxxx |
10xxxxxx |
|
|
U+10000 - U+1FFFFF |
11110xxx |
10xxxxxx |
10xxxxxx |
10xxxxxx |
Les principales caractéristiques de cette conception sont les suivantes :
- les points de code ASCII 0 à 127 sont codés sur un octet. Dans ce cas, le code UTF-8 a la même valeur que le code ASCII. Le bit de poids fort est toujours 0 ;
- les points de code supérieurs à 127 sont représentés par des séquences de plusieurs octets. Le premier octet commence par deux, trois ou quatre « 1 » suivi par un 0. Les octets suivants commencent tous par « 10 » ;
- le nombre de 1 au début du premier octet d'une séquence de plusieurs octets indique le nombre d'octets dans la séquence, de sorte que la longueur de la séquence peut être déterminée sans examiner les octets suivants ;
- les bits restants (indiqués par des x dans le tableau ci-dessus) sont utilisés par le point de code en cours de codage, potentiellement précédé par des 0 si nécessaire ;
- les codes composés d'un seul octet, les premiers octets d'une séquence et les octets de continuation (octets suivants le premier octet d'une séquence de plusieurs octets) ne peuvent pas être confondus. En utilisant différents patterns de reconnaissance, il est donc possible d'identifier le type d'un octet, ce qui permet notamment d'identifier des chaînes incorrectes et d'ignorer les erreurs (si le flux provient du réseau par exemple), d'avancer ou reculer d'un caractère Unicode à la fois sans itérer sur chaque octet, etc.
Si l'on prend par exemple le caractère œ (U+0153) :
- Le point de code étant compris entre U+0080 et U+07FF il sera codé sur deux octets, dont 11 bits sont réservés au point de code ;
- 0x153 correspond en binaire à 0001 0101 0011, les 6 derniers bits (01 0011) composeront le second octet, et les bits 2 à 6 (001 01) composeront le premier. Le premier bit (0) est quant à lui ignoré ;
- En partant du modèle 110xxxxx 10xxxxxx, nous remplaçons les x par les valeurs calculées dans le point 2 ce qui donne 1100 0101 1001 0011 ou 0x12 0x05 0x09 0x03.
La spécification du standard est disponible à l'adresse suivante : http://www.ietf.org/rfc/rfc3629.txt
XI-D-3-a. Codage trop long▲
La norme précise que le codage correct d'un point de code, doit utiliser uniquement le nombre minimum d'octets nécessaires pour contenir les bits significatifs du point de code. Cette règle permet de garder une correspondance un à un entre les points de code et de leur codage, de sorte qu'il existe un codage valable unique pour chaque point de code. Permettre plusieurs codages rendrait les tests d'égalité entre les chaînes de caractères plus compliqués à définir.
XI-D-4. UTF-8 modifié▲
Les différences entre l'UTF-8 et l'UTF-8 modifié sont les suivantes :
- le caractère NULL est codé en utilisant le format sur 2 octets, de fait les chaînes de caractères ne contiennent jamais le caractère NULL, ce qui leur permet d'être traitées par des fonctions traditionnelles pour lesquelles le caractère NULL est un marqueur de fin de chaîne ;
- seulement les formats sur 1, 2 et 3 octets sont utilisés ;
- les caractères supplémentaires sont codés en codant séparément les unités de code de leur représentation UTF-16. Chaque demi-zone d'indirection (unité de code) est représentée sur 3 octets, et donc un caractère supplémentaire est codé sur 6 octets.
Le codage d'un caractère supplémentaire a pour modèle :
2.
3.
4.
5.
6.
7.
8.
9.
// Unité de code 1
1110aaaa 10bbxxxx 10xxxxxx
// Unité de code 2
1110aaaa 10ccxxxx 10xxxxxx
où aaaa = 1101 = 0xD
bb = 10 puisque correspondant à une valeur entre Ox8 et 0xB
cc = 11 puisque correspondant à une valeur entre OxC et 0xF
Pour rappel, la zone d'indirection haute est comprise entre 0xD800 et 0xDBFF et la zone d'indirection basse entre 0xDC00 et 0xDFFF.
XI-D-5. BOM▲
Le BOM ou Byte Order Mark (indicateur de l'ordre des octets) est un caractère Unicode utilisé pour signaler le boutisme (ordre des octets) d'un fichier texte ou un flux. Il a pour point de code U+FEFF. L'utilisation du BOM étant facultative, s'il est utilisé, il doit être présent au début du flux. Au-delà de son utilisation spécifique comme un indicateur d'ordre des octets, le BOM permet aussi d'indiquer, la transformation Unicode utilisée.
XI-D-5-a. UTF-8▲
L'UTF-8 peut contenir un BOM, cependant, il n'est ni requis de l'utiliser, ni recommandé. En UTF-8 les caractères étant interprétés comme une séquence d'octets, le boutisme n'a aucun impact. Le BOM est utilisé comme une signature, indiquant qu'un fichier est codé en UTF-8.
XI-D-5-b. UTF-16 et UTF-32▲
En UTF-16 (et UTF-32), le BOM peut être placé au début d'un flux pour indiquer le boutisme de toutes les unités de code de 16 bits (32 pour l'UTF-32) du flux.
- Si les unités de 16 bits sont représentées dans l'ordre big-endian, le caractère BOM apparaîtra dans la séquence d'octets 0xFE suivie par 0xFF.
- Si les unités de 16 bits sont représentées dans l'ordre little-endian, la séquence d'octets sera 0xFF suivis par 0xFE.
En résumé
|
Codage |
Représentation |
|
UTF-8 |
EF BB BF |
|
UTF-16 Big Endian |
FE FF |
|
UTF-16 Little Endian |
FF FE |
|
UTF-32 Big Endian |
00 00 FE FF |
|
UTF-32 Little Endian |
FF FE 00 00 |
XI-E. Longueur d'une chaîne de caractères▲
Calculer la longueur d'une chaîne de caractères Unicode ou trouver la position d'un caractère peut s'avérer un peu compliqué, car il existe quatre approches différentes auxquelles s'ajoute le risque de confusion causé par la combinaison des caractères. Le choix de la méthode de comptage à utiliser dépendra donc de ce qui doit être compté et de l'utilisation du résultat.
Chacune des quatre approches est illustrée à l'aide de la chaîne de caractères suivante : U+0061 U+0928U+093F U+4E9C U+10083 . Cette chaîne de caractères se compose :
- de la lettre minuscule latine a (U+0061) ;
- suivie par la syllabe Devanagari « ni » (qui est représenté par la syllabe « na » et la combinaison caractère voyelle « i ») (U+0928, U+093F) ;
- suivie d'un idéogramme commun Han (U+4E9) ;
- et enfin d'un idéogramme en linéaire B signifiant un « équidé » (U+10083) :

Nous pouvons compter les choses suivantes :
- Des octets ;
- Des unités de code ;
- Des points de code ;
- Des graphèmes.
1. Connaître le nombre d'octets d'une chaîne de caractères peut être nécessaire si l'on souhaite savoir la taille qu'elle prend en mémoire.
Voyons le détail pour les codages UTF-8, UTF-16 et UTF-32 :
|
Codage |
Nombre d'octets |
Séquence d'octets |
|
UTF-8 |
14 |
61 E0 A4 A8 E0 A4 BF E4 BA 9C F0 90 82 83 |
|
UTF-16 |
12 |
00 61 09 28 09 3F 4E 9C D8 00 DC 83 |
|
UTF-32 |
20 |
00 00 00 61 00 00 09 28 00 00 09 3F 00 00 4E 9C 00 01 00 83 |
2. Connaître le nombre d'unités de code d'une chaîne de caractères peut être nécessaire lorsque l'on indique la taille d'un tableau de caractères ou l'on souhaite avoir la position d'un caractère. En considérant que la taille du type du caractère est égale à la taille d'une unité de code.
Voyons le détail pour les codages UTF-8, UTF-16 et UTF-32 :
|
Codage |
Nombre d'unités de code |
Séquence d'octets |
|
UTF-8 |
14 |
61 E0 A4 A8 E0 A4 BF E4 BA 9C F0 90 82 83 |
|
UFT-16 |
6 |
0061 0928 093F 4E9C D800 DC83 |
|
UTF-32 |
5 |
00000061 00000928 0000093F 00004E9C 00010083 |
3. Il peut être parfois utile de connaître le nombre de points de code quel que soit l'encodage. À noter qu'en UTF-32 le comptage du nombre de points de code dans une chaîne de caractères est identique à celui du nombre d'unités de code.
L'exemple contient 5 points de code, U+0061, U+0928, U+093F, U+4E9C et U+10083.
4. La dernière chose que l'on puisse compter est le nombre de graphèmes (caractères perçus par l'utilisateur). Dans notre exemple, la syllabe Devanagari « ni » doit être composé en utilisant un caractère de base « na » (न), suivi par une voyelle combinant le son « i » (ि), bien que les utilisateurs finals voient et pensent de la combinaison des deux (नि) comme une seule unité de texte. En ce sens, la chaîne d'exemple peut être considérée comme contenant 4 « caractères ».
XI-F. Manipulation de chaînes de caractères en Java▲
En Java, la façon la plus commune d'assigner une chaîne de caractères à une variable s'effectue de la manière suivante :
final String s1 = "abcdefghij";
Mais il est aussi possible d'instancier la classe String :
final String s2 = new String("abcdefghij");
Néanmoins, lors de la compilation en bytecode, le premier cas sera traduit par une simple instruction ldc (ou ldc_wen fonction du contexte), alors que le second nécessitera l'utilisation d'instructions relatives à l'instanciation de classes (instructions que nous verrons prochainement).
Vérifions que les deux chaînes sont bien égales :
2.
3.
4.
5.
6.
7.
@Test
public void stringEquality0() {
final String s1 = "abcdefghij";
final String s2 = new String("abcdefghij");
Assert.assertEquals(s1, s2);
}
Nous pouvons aussi préciser le codage de la chaîne de caractères :
final String s2 = new String("abcdefghij".getBytes(), "UTF-8");
Une fois de plus, un test unitaire nous confirme l'égalité de deux chaînes :
2.
3.
4.
5.
6.
7.
@Test
public void stringEquality1() throws UnsupportedEncodingException {
final String s1 = "abcdefghij";
final String s2 = new String("abcdefghij".getBytes(), "UTF-8");
Assert.assertEquals(s1, s2);
}
Mais attention. Instancier une chaîne de caractères en précisant un codage, ne va pas convertir la chaîne dans le codage indiqué :
2.
3.
4.
5.
6.
7.
@Test
public void stringEquality2() throws UnsupportedEncodingException {
final String s1 = "abcdefghij";
final String s2 = new String("abcdefghij".getBytes(), "UTF-16");
Assert.assertFalse(s1.equals(s2));
}
À présent, s1 et s2 ne sont plus égaux. Essayons de voir pourquoi, en affichant chaque caractère de chacune des chaînes :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
@Test
public void stringEquality3() throws UnsupportedEncodingException {
final String s1 = "abcdefghij";
final String s2 = new String("abcdefghij".getBytes(), "UTF-16");
System.out.println("---- s1 ----");
for(char c : s1.toCharArray()) {
System.out.print(c + " ");
}
System.out.println("\n---- s2 ----");
for(char c : s2.toCharArray()) {
System.out.print(c + " ");
}
}
Le test précédent affiche :
---- s1 ----
a b c d e f g h i j
---- s2 ----
慢 捤 敦 杨 楪Note : s2 peut être représenté de manière différente en fonction de l'environnement d'exécution.
Les caractères de s1 sont donc bien affichés, contrairement à ceux de s2. Mais ceci ne démontre pas grand-chose. Pour prouver que s2, n'a pas été converti en UTF-16, nous devons récupérer le point de code de chaque caractère :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
@Test
public void stringEquality4() throws UnsupportedEncodingException {
final String s1 = "abcdefghij";
final String s2 = new String("abcdefghij".getBytes(), "UTF-16");
System.out.println("---- s1 ----");
for(int i = 0; i < s1.length(); i++) {
final int codePoint = s1.codePointAt(i);
System.out.print(codePoint + " ");
}
System.out.println("\n---- s2 ----");
for(int i = 0; i < s2.length(); i++) {
final int codePoint = s2.codePointAt(i);
System.out.print(codePoint + " ");
}
}
Le résultat du test est le suivant :
---- s1 ----
97 98 99 100 101 102 103 104 105 106
---- s2 ----
24930 25444 25958 26472 26986Sans surprise, les points de code de la chaîne s1 sont corrects et ceux de s2 ne le sont pas.
Pourquoi ? Avant de rentrer dans les détails, faisons un dernier test. Il serait intéressant de savoir ce que retourne la méthode getBytes().
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
@Test
public void stringEquality5() throws UnsupportedEncodingException {
final String s1 = "abcdefghij";
final String s2 = new String("abcdefghij".getBytes(), "UTF-16");
System.out.println("---- s1 ----");
for(byte b : s1.getBytes()) {
System.out.print(this.byteToHex(b) + " ");
}
System.out.println("\n---- s2 ----");
for(byte b : s2.getBytes()) {
System.out.print(this.byteToHex(b) + " ");
}
}
Le test affiche :
---- s1 ----
61 62 63 64 65 66 67 68 69 6A
---- s2 ----
E6 85 A2 E6 8D A4 E6 95 A6 E6 9D A8 E6 A5 AAoù s2 peut avoir une forme différente en fonctionnement de l'environnement d'exécution. Si s2 avait été converti en UTF-16, nous aurions eu :
00 61 00 62 00 63 00 64 00 65 00 66 00 67 00 68 00 69 00 6AFinalement, qu'avons-nous démontré ? La réponse ne peut être plus simple. Nous n'avons absolument rien démontré, nous n'avons fait qu'accumuler les erreurs, et ceci, depuis le second exemple. Preuve qu'un mauvais test peut laisser à penser que du code est correct alors que l'on se trompe complètement.
Reprenons tout depuis le début en mettant le code de côté et en nous focalisant sur le compilateur, la JVM et la plate-forme.
Tout fichier texte est codé dans un système de codage. Les fichiers source Java n'échappent pas à cette règle. De fait, il est impératif de préciser au compilateur le codage des fichiers .java. Il va sans dire que toutes les sources (fichiers .java) d'une même application (ou bibliothèque) doivent avoir le même codage.
En utilisant javac, nous avons à notre disposition l'option -encoding (tous les outils de construction permettent aussi d'indiquer le codage qui sera utilisé par le compilateur, comme cela a été fait dans le fichier macros.xml que nous utilisons) :
javac -encoding UTF-8 MyFile.java
Note : la casse n'a pas d'importance et le tiret de séparation entre un système de codage et le nombre qui le suit est optionnel. Les valeurs UTF8, utf-8 et utf8 sont aussi valides.
Vous trouverez tous les codages supportés par Java sur le site d'Oracle.
En indiquant un type de codage des fichiers source, le compilateur est à même de convertir toutes les chaînes de caractères en UTF-8 modifié. Puisqu'il faut garder à l'esprit que d'une manière générale, déterminer le type de codage d'un fichier sans aucune information est quasiment impossible, surtout lorsque l'on peut en utiliser plusieurs. Concernant javac, si l'option -encoding n'est pas précisée, il utilise le codage du système d'exploitation sur lequel il est exécuté, c'est-à-dire UTF-8 pour la plupart des OS Linux récents et FreeBSD, CP-1252 pour les versions occidentales de Windows, etc.
De fait, laisser le compilateur choisir le codage des fichiers sources est plus que déconseillé.
Le fait que toutes les chaînes de caractères d'un fichier .class soient codées en UTF-8 modifié, permet d'avoir un fichier de taille réduite, ce qui à l'origine de Java était une nécessité. En effet, comme nous l'avons vu dans le premier article de la série (Part 0 - Sneak Peek) l'un des intérêts de Java était de pouvoir exécuter des fichiers compilés envoyés au travers du réseau - comme c'est le cas des Applets - or à la fin des années 90, les connexions Internet étant lentes, il fallait minimiser la taille d'une application au minimum.
De plus, le fait de n'avoir qu'un seul type de codage permet à la JVM, de ne pas se poser de questions lorsqu'elle charge des fichiers .class. Comme mentionné dans l'introduction, les chaînes de caractères codées en UTF-8 modifié dans un fichier .class sont converties à UTF-16 par la JVM. Nous y reviendrons. Mais avant, repartons du second exemple.
La chaîne de caractères "abcdefghij" est égale à new String("abcdefghij".getBytes(), "UTF-8") :
- puisque tous les fichiers de notre projet sont en UTF-8. Si nous utilisions un autre codage, le test serait en erreur ;
- mais aussi, car nous utilisons des caractères dont le point de code est inférieur à 8 bits. Or presque tous les systèmes de codage (ne les connaissant pas tous et dans le doute, nous considérerons que cette règle ne s'applique pas à tous les systèmes de codage) ont les mêmes 128 premiers caractères. De plus, hormis l'UTF-16 et l'UTF-32, les types de codage pour la majorité des systèmes d'écriture occidentaux codent les caractères sur 1 octet. De fait, sous Windows, pour la chaîne la méthode "abcdefghij", la méthode getBytes() retourne un tableau de bytes ayant les mêmes valeurs que sous Linux, et ceci, bien que Windows et Linux n'utilisent pas le même codage par défaut. Mais pourquoi est-il question du codage du système d'exploitation ? La réponse se trouve dans la javadoc de la méthode getBytes() : « Code cette String en une séquence d'octets en utilisant le codage par défaut de la plate-forme, en stockage le résultat dans un nouveau tableau de bytes ». Tout comme l'option -encoding du compilateur, il est judicieux de passer en paramètre de la méthode getBytes() le type de codage dans lequel nous souhaitons que la chaîne de caractères soit convertie : getBytes(« UTF-8 »).
Si nous résumons, notre chaîne de caractères est codée en UTF-8 modifié dans le fichier .class, puis convertie en UTF-16 par la JVM. Lorsque nous appelons la méthode getBytes("UTF-8"), elle est encodée en UTF-8 puis transformée en tableau de bytes. Tout ceci nous permet d'instancier une classe String en utilisant le tableau de bytes et le codage « UTF-8 ».
Avec nos nouvelles connaissances, nous pouvons donc réécrire la méthode stringEquality2() :
2.
3.
4.
5.
6.
7.
@Test
public void stringEquality6() throws UnsupportedEncodingException {
final String s1 = "abcdefghij";
final String s2 = new String("abcdefghij".getBytes("UTF-16"), "UTF-16");
Assert.assertTrue(s1.equals(s2));
}
Passons rapidement en revue les autres exemples.
Lorsque l'on exécute la méthode stringEquality3(), les caractères de s2 correspondent aux caractères ayant pour point de code les valeurs affichées par la méthode stringEquality4(). Le tableau de bytes ayant été utilisé pour créer s2 étant considéré comme étant codé en UTF-16, chaque paire i et i+1 est considérée comme un caractère. Par exemple :
0x61 << 8 | 0x62 = 24930
Et pour finir, si la méthode stringEquality5() n'affiche pas les bonnes valeurs hexadécimales, c'est que nous appelons getBytes() (sous Windows, dont le codage par défaut est CP-1252) sur une chaîne s2 qui est - mal - codée en UTF-16.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
@Test
public void stringEquality7() throws UnsupportedEncodingException {
final String s1 = "abcdefghij";
final String s2 = new String("abcdefghij".getBytes("UTF-8"), "UTF-16");
System.out.println("---- s1 ----");
for (byte b : s1.getBytes("UTF-8")) {
System.out.print(this.byteToHex(b) + " ");
}
System.out.println("\n---- s2 ----");
for (byte b : s2.getBytes("UTF-16")) {
System.out.print(this.byteToHex(b) + " ");
}
}
Le test affiche :
---- s1 ----
61 62 63 64 65 66 67 68 69 6A
---- s2 ----
FE FF 61 62 63 64 65 66 67 68 69 6AAvant de conclure, revenons sur le fait que la JVM manipule des chaînes en UTF-16.
Mentionnons tout d'abord que c'est pour cette raison que le type char a une taille de 2 octets.
char c = '\u03F4';
Note : la notation \uXXXX permet d'écrire en Java, un caractère ou une chaîne de caractères sous forme d'une séquence de points de code.
Si vous vous souvenez de ce que l'on a vu précédemment concernant les caractères codés en UTF-16, ils tiennent sur 2 ou 4 octets. C'est dans ces moments qu'on se rend compte que les bons/mauvais choix ne se jouent qu'à un fil. Java a été créé en 1991 et la version première publique date de 1995. Un an plus tard, la version 2 d'Unicode sort et les caractères ne sont plus limités à 16 bits (2 octets). Ceci a en réalité très peu d'impact pour la majorité des cas, puisqu'il est assez rare d'utiliser des caractères n'appartenant pas au Plan Multilingue de Base. Mais il est tout de même bon de savoir :
- qu'il n'est pas possible d'écrire char c = '\u10083'; ou tout point de code supérieur à 0xffff ;
- et que
"\u10083".length() retourne 2 et non 1.
Néanmoins, la classe Character permet de manipuler - plus ou moins simplement - les caractères des plans supplémentaires.
XI-G. What's next ?▲
Si vous souhaitez en savoir plus sur l'Unicode, la spécification et la FAQ sont les points d'entrée à consulter en priorité.
Concernant Java, il y a encore beaucoup à dire. Mais le principe est le suivant :
- toutes les constantes de type chaînes de caractères ne doivent pas être instanciées en utilisant les constructeurs String(…), à moins d'avoir une très bonne raison ;
- ne jamais utiliser le codage de la plate-forme sous peine d'avoir de gros soucis ;
- la conversion d'une chaîne de caractères ou l'indication du type de codage d'un flux d'octets, ne doivent être faites que dans deux situations : (1) à la réception d'un flux et (2) à l'envoi d'un flux (réception et envoi, s'appliquent à un fichier, des données venant du réseau, etc.), en d'autres termes, un flux externe à l'application. À noter que pour le XML et le JSON, il n'y a pas à se soucier du type de codage, les nombreuses bibliothèques existantes (permettant de convertir un flux en objet Java) s'en chargent pour vous.
Mais nous aurons l'occasion d'y revenir dans de prochains articles de la série.