



I. Le « challenge »▲

Le « challenge » ici est de produire un fichier JSON valide à l'issue d'un traitement batch, tout en gardant la même flexibilité de configuration du job que celle offerte par les classes FlatItemWriter et StaxEventItemWriter.
Notre idée est d'explorer le framework Spring Batch, à la recherche de la logique au cœur de l'écriture dans des fichiers pour l'adapter à notre besoin.
Pour illustrer la problématique à résoudre, nous partons d'un cas simple :
- Lire des noms et prénoms de personnes depuis un fichier texte ;
- Les transformer en (lettres) capitales ;
- Écrire le résultat dans un fichier JSON valide.
Nous commencerons par explorer la boîte à outils du framework pour voir ce qui nous sera utile dans notre démarche. Puis, nous présenterons rapidement la notion de thread-safety ou plutôt de non thread-safety des implémentations d'itemwriter par défaut.
Avant de présenter notre solution, JsonFlatFileItemWriter, nous commencerons par présenter les limites de l'implémentation FlatItemWriter (la classe StaxEventItemWriter étant mise de côté, car ne générant que du XML) par rapport à notre besoin.
Vous l'aurez deviné, ce billet ne reviendra pas sur les grands principes de Spring batch, il existe de bonnes documentations ici et là pour bien démarrer avec le framework.
Le code ainsi et les ressources de ce billet sont disponibles sur le Github de Soat.
II. Exploration de la boîte à outils de Spring Batch▲
Pour les opérations d'écritures, Spring Batch fournit les interfaces et la classe abstraite suivantes :
- ItemWriter : interface générique permettant de gérer les opérations d'écriture vers un support, quel qu'il soit (fichier, base de données…). Définit la méthode :
write(List<?extendsT>) qui est implémentée systématiquement pour les opérations d'écriture ; - AbstractItemStreamItemWriter : classe abstraite, mère de toutes les classes implémentant l'interface ItemWriter. StaxEventItemWriter et FlatFileItemWriter l'étendent ;
- ItemStream : interface permettant de sauvegarder périodiquement l'état d'un traitement et reprendre un traitement stoppé (en cas d'erreur, par exemple) au niveau d'arrêt du traitement précédent ;
- ResourceAwareItemWriterItemStream : interface commune des Itemwriters qui implémentent ItemStream et écrivent dans une ressource de sortie (au sens Spring) ;
- LineAggregator : interface permettant de définir la logique de sérialisation d'un objet du modèle sous la forme d'une chaîne de caractères ;
- FlatFileHeaderCallback : interface de callback permettant d'écrire un en-tête (header) dans un fichier ;
- FlatFileFooterCallback : interface de callback permettant d'écrire un pied de page (footer) dans un fichier.
Pour les opérations d'écriture dans les fichiers, Spring Batch fournit des implémentations d'Itemwriter dédiées à la production de fichiers texte (plus ou moins complexes) et de fichiers XML.
Pour rappel, ces classes sont définies telles que :
2.
public class StaxEventItemWriter extends AbstractItemStreamItemWriter implements
ResourceAwareItemWriterItemStream,InitializingBean
2.
public class FlatFileItemWriter extends AbstractItemStreamItemWriter implements
ResourceAwareItemWriterItemStream,InitializingBean
III. Des ItemWriters non thread-safe▲
Dans la documentation des implémentations de l'ItemWriter mentionnées plus haut, il est commun de trouver la précision suivant laquelle la classe n'est pas thread-safe :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
/**
* This class is an item writer that writes data to a file or stream. The writer
* also provides restart. The location of the output file is defined by a
* {@link Resource} and must represent a writable file.<br>
*
* Uses buffered writer to improve performance.<br>
*
* The implementation is <b>not</b> thread-safe.
*
* @author Waseem Malik
* @author Tomas Slanina
* @author Robert Kasanicky
* @author Dave Syer
* @author Michael Minella
*/
public class FlatFileItemWriter<T> extends AbstractItemStreamItemWriter<T> implements ResourceAwareItemWriterItemStream<T>,
InitializingBean {
Étant donné que notre writer s'inspire du fonctionnement de ces deux classes (StaxEventItemWriter et FlatFileItemWriter), il convient de revenir sur la raison pour laquelle ce dernier aura la même limitation.
III-A. Spring batch et la notion de classe « thread-safe »▲
Par défaut, les jobs et steps spring sont monothreadés :
Many batch processing problems can be solved with single threaded, single process jobs, so it is always a good idea to properly check if that meets your needs before thinking about more complex implementations. Measure the performance of a realistic job and see if the simplest implementation meets your needs first: you can read and write a file of several hundred megabytes in well under a minute, even with standard hardware.
Les steps d'un job donné sont exécutés de façon séquentielle au sein d'un même thread. Vu depuis le job, un traitement classique se déroule suivant le modèle de la figure ci-dessous.
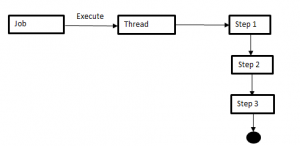
Dans le cadre d'un environnement multithreadé, il n'est pas garanti que le fichier (puisque c'est ce que nous voulons avoir finalement) soit dans un état cohérent du fait de l'accès concurrent activé.
Nous avons voulu savoir pourquoi ils n'ont pas juste optimisé ces classes par défaut pour des environnements multithreadés. La réponse tient en deux volets :
- Dans le code, aucune portion de code de ces classes ne gère les accès concurrents ;
- Les beans Spring sont « Stateful » : elles ont besoin de gérer la reprise de l'exécution d'une tâche suite à une interruption, là où la précédente exécution s'est arrêtée (restart). Et, dans le cas des fichiers, elles ont également besoin de maintenir leur état de traitement afin de savoir quand écrire l'en-tête (FlatFileHeaderCallback) et/ou le pied de page (FlatFileFooterCallback) notamment.
Cette interrogation levée, nous pouvons fermer cette parenthèse et revenir au writer custom produisant du JSON.
IV. FlatItemWriter ne produit pas du JSON valide !▲
Quand on sait qu'il est possible de produire des fichiers texte plus ou moins complexes avec FlatFileItemWriter, il est tentant de l'utiliser pour la génération du JSON.
Avec de l'imagination (débordante, pour le coup), il est peut-être possible d'arriver au résultat attendu. Ayant essayé cette solution dans un premier temps, nous n'avons obtenu qu'un JSON invalide. Et c'est logique.
En effet, pour traiter correctement un fichier JSON dans le cadre d'un batch, il faut tenir compte des contraintes liées au format.
Un fichier JSON valide ; contenant une liste d'objets peut se décomposer comme suit :

IV-A. Cas de test▲
Soit le fichier texte contenant les noms et prénoms ci-dessous :
2.
3.
4.
5.
Toto,Titi
Titi,Toto
Tata,Toto
Titi,Tata
Tata,Toto
Objectif 1 : lire les noms et prénoms de ce fichier, les transformer en (lettres capitales), puis écrire le résultat dans un fichier texte basique.
Objectif 2 : répéter la même action, mais en écrivant le résultat dans un fichier JSON. FlatItemWriter pour écriture dans un fichier texte (objectif 1).
Dans les configurations présentées plus bas, le processus de lecture est occulté, car hors scope.
Nous nous concentrons uniquement sur la partie de l'écriture dans le fichier.
IV-A-1. Configuration de FlatItemWriter pour l'objectif 1▲
Étape 1 : implémentation de LineAggregator : format chaîne de caractères de l'objet à sérialiser dans le fichier suivi d'un retour à la ligne :
2.
3.
4.
5.
6.
7.
8.
public class PersonLineAggregator<Person> implements LineAggregator<Person> {
@Override
public String aggregate(Person person) {
//LINE_SEPARATOR = System.getProperty("line.separator");
return person.toString() + AppUtils.LINE_SEPARATOR;
}
}
Étape 2 : définition optionnelle d'un en-tête et d'un pied de page pour le fichier attendu :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
public class PersonHeaderFooterCallBack implements FlatFileHeaderCallback, FlatFileFooterCallback{
private static final String OUTPUT_HEADER = "#Persons";
private static final String OUTPUT_FOOTER = "#eof";
@Override
public void writeHeader(Writer writer) throws IOException {
writer.write(OUTPUT_HEADER + AppUtils.LINE_SEPARATOR);
}
@Override
public void writeFooter(Writer writer) throws IOException {
writer.write(OUTPUT_FOOTER);
}
}
Étape 3 : configuration de FlatItemWriter pour l'écriture :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
@Bean
public ItemWriter<Person> writer() {
FlatFileItemWriter<Person> writer = new FlatFileItemWriter<Person>();
writer.setLineSeparator(AppUtils.COMMA_SEPARATOR);
writer.setLineAggregator(new PersonLineAggregator<Person>());
//Setting header and footer.
PersonHeaderFooterCallBack headerFooterCallback = new PersonHeaderFooterCallBack();
writer.setHeaderCallback(headerFooterCallback);
writer.setFooterCallback(headerFooterCallback);
writer.setEncoding(AppUtils.UTF_8.name());
writer.setShouldDeleteIfExists(true);
writer.setResource(new FileSystemResource(System.getProperty("user.dir") + File.separator + TARGET_SAMPLE_OUTPUT_DATA_TXT));
return writer;
}
Résultat de l'objectif 1 : fichier exploitable en l'état :
2.
3.
4.
5.
6.
7.
#Persons,
[lastname=TITI, firstname=TOTO],
[lastname=TOTO, firstname=TITI],
[lastname=TOTO, firstname=TATA],
[lastname=TATA, firstname=TITI],
[lastname=TOTO, firstname=TATA],
#eof
Ce format de texte peut convenir en l'état ou faire l'objet d'autres modifications, mais n'est pas inexploitable comme le deuxième cas ci-dessous.
IV-A-2. Configuration de FlatItemWriter pour objectif 2▲
Pour cette partie, nous considérons passer par Jackson pour sérialiser le modèle métier en chaîne de caractères.
Étape 1 : nouvelle implémentation de LineAggregator : format de l'objet JSON à sérialiser dans le fichier :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
...
public class PersonJsonItemAggregator<Person> implements LineAggregator<Person> {
...
@Override
public String aggregate(Person person) {
String result = null;
try {
result = JsonUtils.convertObjectToJsonString(person);
} catch (JsonProcessingException jpe) {
logger.error("An error has occured. Error message {} ", jpe.getMessage() );
}
return result;
}
}
Étape 2 : définition obligatoire d'un en-tête et d'un pied de page pour le fichier attendu :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
public class PersonHeaderFooterCallBack implements FlatFileHeaderCallback, FlatFileFooterCallback{
private static final String JSON_ROOT_NODE = "Persons";
private JsonWriter jsonWriter;
@Override
public void writeHeader(Writer writer) throws IOException {
this.jsonWriter = new JsonWriter(writer);
jsonWriter.beginObject().name(JSON_ROOT_NODE).beginArray();
}
@Override
public void writeFooter(Writer writer) throws IOException {
jsonWriter.endArray().endObject();
jsonWriter.close();
}
}
Étape 3 : configuration de FlatItemWriter pour l'écriture du JSON :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
@Bean
public ItemWriter<Person> writer() {
FlatFileItemWriter<Person> writer = new FlatFileItemWriter<Person>();
writer.setLineSeparator(AppUtils.COMMA_SEPARATOR);
//Setting header and footer.
PersonHeaderFooterCallBack headerFooterCallback = new PersonHeaderFooterCallBack();
writer.setHeaderCallback(headerFooterCallback);
writer.setFooterCallback(headerFooterCallback);
writer.setLineAggregator(new PersonJsonItemAggregator<Person>());
writer.setResource(new FileSystemResource(System.getProperty("user.dir") + File.separator + TARGET_SAMPLE_OUTPUT_DATA_JSON));
writer.setEncoding(AppUtils.UTF_8.name());
writer.setShouldDeleteIfExists(true);
return writer;
}
Résultat de l'objectif 2 : fichier inexploitable, car ne respectant pas le format JSON.
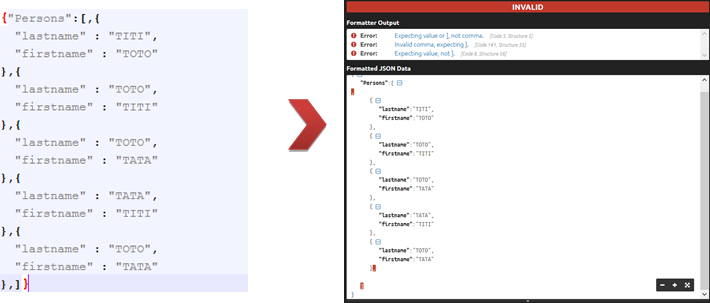
C'est exactement ce problème de validation de JSON que nous avons voulu résoudre en implémentant une solution custom, réutilisable et flexible au niveau de la configuration.
V. La solution custom▲
Bibliothèques nécessaires à l'écriture de l'API :
- Jackson-databind (version 2.4.6) : ObjectMapper nous permet de sérialiser un objet en JSON sans effort dans la classe JsonUtils ;
- Gson (version 2.31) : nous permet d'écrire le callback du header et footer sans effort avec la classe JsonWriter ;
- Java 5 ou plus récent.
Cette classe suit la définition des FlatFileItemWriter et de StaxEventItemWriter et se présente telle que :
2.
3.
4.
5.
6.
7.
8.
/**
* Custom writer implementation made to output json format.
*
* @author Michelle AVOMO
*
*/
public class JsonFlatFileItemWriter<T> extends AbstractItemStreamItemWriter<T>
implements ResourceAwareItemWriterItemStream<T>, InitializingBean
Pour reprendre le deuxième objectif présenté plus haut, la configuration globale se définit comme sur l'exemple ci-après :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
@Bean
public ItemWriter<Person> writer() {
//JSON_ROOT_NODE = persons but can be null and in that case just call the default constructor
JsonFlatFileItemWriter<Person> writer = new JsonFlatFileItemWriter<Person>(JSON_ROOT_NODE);
writer.setJsonItemAggregator(new JsonItemAggregator<Person>());
writer.setResource(new FileSystemResource(System.getProperty("user.dir") + File.separator + TARGET_SAMPLE_OUTPUT_DATA_JSON));
writer.setEncoding(AppUtils.UTF_8.name());
writer.setShouldDeleteIfExists(true);
return writer;
}
VI. Récapitulatif▲
Étape 1 : instanciation de notre JsonFlatFileItemWriter : le paramètre passé en entrée du constructeur est facultatif
JsonFlatFileItemWriter<Person> writer = new JsonFlatFileItemWriter<Person>(JSON_ROOT_NODE);
Étape 2 : définition de l'instance de LineAggregator renommé au vu contexte en JsonItemAggregator
writer.setJsonItemAggregator(new JsonItemAggregator<Person>());
Ici, nous avons repris la même logique de LineAggregator de l'objectif 2 (jackson-databind définit la logique de sérialisation du Pojo dans le fichier de sortie) et rendu le tout générique.
Étape 3 : Définition du chemin du fichier de sortie attendu
writer.setResource(new FileSystemResource(System.getProperty("user.dir") + File.separator + TARGET_SAMPLE_OUTPUT_DATA_JSON));
Les autres étapes de configuration de l'encodage du texte et de suppression ou non de fichiers déjà existants sont facultatives.
Étape 4 : il n'y a pas d'étape 4. Vous pouvez lancer le traitement.
Résultat suite à la solution custom

JSON valide en sortie.
VII. Conclusion▲
Dans la solution proposée, nous avons gardé à l'esprit la flexibilité de configuration de Spring Batch. La solution finale requiert même moins de lignes de configuration que les versions existantes, tout simplement parce que nous avons identifié l'écriture du header et du footer, ainsi que celle des délimiteurs (virgule et espace), comme toujours vraie dans le cadre d'un fichier JSON.
VIII. Remerciements ▲
Cet article a été publié avec l'aimable autorisation de la société Soat.
Nous tenons à remercier Claude Leloup pour la relecture orthographique, et Malick SECK pour la mise au gabarit.