





I. Introduction▲

Dans le projet de l'OpenJDK, il y a l'implémentation de référence du JDK bien sûr ; mais c'est également une grosse boîte à outils pour le développeur ! On y trouvera notamment, JMH, un framework de benchmarking Java. Dans un précédent article, nous avons vu comment l'utiliser pour écrire un benchmark d'un programme Java, mesurer des temps d'exécution et un throuhput moyen (opérations par seconde). Mais comment JMH réalise-t-il ses calculs ? Sur quel ensemble de données peut-il se baser ? Peut-on tweaker JMH pour affiner le résultat ? Comment l'interpréter ? C'est ce que nous allons voir à présent…
II. JMH, sous le capot▲

Lors de mon précédent post, nous avons vu qu'il était illusoire de benchmarker un morceau de code sur une unique exécution, tant les résultats pouvaient varier d'un run à l'autre. C'est pour cette raison que JMHJMH se base sur des cycles itératifs d'exécution du code testé. Nous allons voir à présent comment il itère, et de quelles différentes façons les mesures peuvent être prises.
II-A. Itérations▲

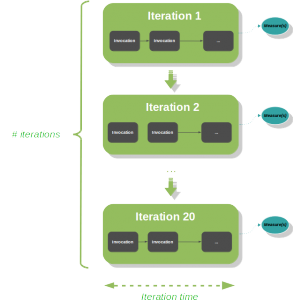
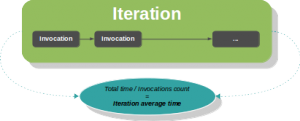
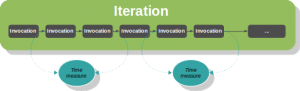
Dans la terminologie JMH, on appelle opération le morceau de code benchmarké, et invocation son exécution unitaire. Dans un benchmark, on effectue non pas une invocation, mais une série d'invocations (en boucle), que l'on appelle itération. Par ailleurs, un benchmark est constitué d'une séquence d'itérations.
Dans le code du benchmark, on utilise l'annotation @Measurement(iterations, time) pour configurer le nombre et éventuellement la durée des itérations.
2.
3.
4.
5.
6.
@Benchmark
@Measurement(iterations = 20, time = 2000, timeUnit = TimeUnit.MILLISECONDS) // 20 iterations of 2000ms each
public void benchmarkSomething() {
// Here is a sample benchmark
// ....
}
Durant les itérations, des temps d'exécution sont mesurés.
II-B. WARMUP itérations▲

Quand on mesure la performance d'un code, on peut :
- Soit mesurer son temps d'exécution « à froid », lors des premiers appels (bytecode interprété) ;
- Soit le mesurer « à chaud » (bytecode compilé par le JIT et optimisé par la JVM).
JMH inclut donc, par défaut dans ses benchmarks, une phase de chauffe de la JVM (« warm up » itérations) durant laquelle on exécutera le code « à blanc » (sans prendre de mesure) : pendant cette phase, la JVM aura le temps d'allouer les ressources nécessaires, et de compiler le bytecode afin de mesurer les temps d'exécution « à chaud ».
Pour configurer les « warmup » iterations, on ajoute une annotation @Warmup, paramétrée comme @Measurement dans le code du benchmark :
2.
3.
4.
5.
6.
7.
@Benchmark
@Warmup(iterations = 10, time = 2000, timeUnit = TimeUnit.MILLISECONDS) // 10 warm up iterations without measures
@Measurement(iterations = 20, time = 2000, timeUnit = TimeUnit.MILLISECONDS)
public void benchmarkSomething() {
// Here is a sample benchmark
// ....
}
II-C. JVM Forks▲

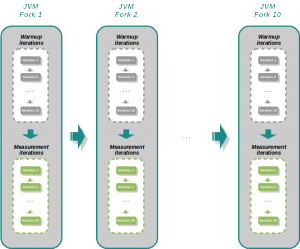
Les performances d'un code Java étant liées à la JVM sur laquelle il tourne, JMH a été doté de la capacité à forker celle-ci, grâce à l'annotation @Forks(value). L'intérêt est double :
- En démarrant de nouvelles JVM, on diminue le risque de performances dégradées à cause d'effets de bord de JMH lui-même, ou dus à « l'usure » de la JVM après un tir (état de la mémoire, threads, etc.) ;
- Par ailleurs, démarrer une nouvelle JVM permet d'appliquer un « tuning » JVM (VM args de performance), semblable à celui de production, par exemple :
2.
3.
4.
5.
6.
7.
8.
@Benchmark
@Fork(value = 10, jvmArgs = {"-server", "-Xmx1g", "-XX:+TieredCompilation"} )
// this will start 10 JVMs like this :
// $ java -server -Xmx1g -XX:+TieredCompilation
public void benchmarkSomething() {
// Here is a sample benchmark
// ...
}
Note : un @Fork(0) désactivera les forks de JVM. Ce mode, déconseillé pour obtenir des mesures fiables, peut néanmoins être intéressant pour pouvoir faire du mode debug depuis son IDE, en démarrant JMH par API…
En réalisant des forks, le benchmark complet se déroule alors de la façon suivante :
II-D. Multithreading▲

Parfois, le code que l'on souhaite benchmarker est en réalité exécuté sur plusieurs threads en même temps dans notre application. Avec JMH, on peut reproduire ce contexte multithreadé, en décorant le benchmark avec l'annotation @Threads(value) :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
@Benchmark
@Threads(4)
public void benchmarkSomething() {
// Here is a sample benchmark run concurrently on 4 threads
// ....
synchronized(lock) {
// bottleneck in execution
// ...
}
// ...
}
Dans cet exemple, la méthode benchmarkée est exécutée sur un pool de quatre threads gérés par JMH ; ainsi, l'overhead dû au bloc synchronized peut être mesuré ! (comme l'on peut s'y attendre, plus le nombre de threads augmente, plus la performance décroît).
NB : ce sujet est très bien illustré dans le blog de Daniel Mitterdorfer, sur l'exemple du SimpleDateFormat qui comme chacun sait n'est pas naturellement thread safe…
III. Des mesures à la hauteur du problème▲

Nous avons vu jusque-là comment configurer les itérations JMH, ainsi que le tuning de la JVM sur laquelle s'exécute le code du benchmark, pour obtenir des conditions d'exécution similaires à celles de la « vraie vie » (production).
À présent, nous allons nous pencher sur les différents «modes» de benchmark proposés par JMH, qui donnent lieu aux prises de mesure, ainsi qu'aux résultats et calculs qui en découlent. Il existe quatre modes, configurables via l'annotation @BenchmarkMode(Mode).
III-A. Mode THROUGHPUT et AVERAGETIME▲
Le mode par défaut de JMH est le mode Throughput (vitesse moyenne d'exécution, en opérations par unité de temps). Il est similaire, car inverse du mode AverageTime (temps moyen d'exécution d'une opération). En voici un exemple :
2.
3.
4.
5.
6.
@Benchmark
@BenchmarkMode(Mode.Throughput)
public void benchmarkSomething() {
// Here is a sample benchmark
// ...
}
Ce mode donne en sortie les résultats suivants :
Result: 42,081 ±(99.9%) 0,154 ops/us [Average]
Statistics: (min, avg, max) = (38,941, 42,081, 43,187), stdev = 0,654
Confidence interval (99.9%): [41,927, 42,236]
# Run complete. Total time: 00:06:42
Benchmark Mode Cnt Score Error Units
benchmarkSomething thrpt 200 42,081 ± 0,154 ops/usLa vitesse moyenne d'exécution de 42 081 ops/µs est obtenue à partir du temps d'exécution moyen, calculé par itération, en comptant le nombre d'invocations faites durant le temps de l'itération (l'attribut time de @Measurement en définit la durée).
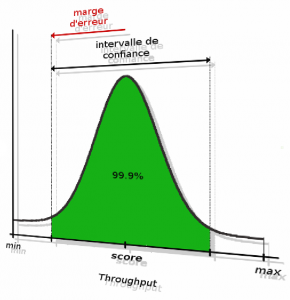
JMH fournit ensuite les statistiques sur l'ensemble des itérations du benchmark :
- le meilleur throughput moyen observé sur une itération (43 187 ops/µs), ainsi que le pire (38 941 ops/µs) ;
- la moyenne sur l'ensemble des itérations (avg), qui est également le score final : 42 081 ops/µs ;
- l'intervalle de confiance à 99,9 % (confidence interval), qui est ici de 41 927 à 42 236 ops/µs (toujours sur l'ensemble des itérations) ;
- la marge d'erreur ;
- l'écart type (stdev) ;
- le nombre d'itérations réalisées : 200 (Cnt).
On peut représenter visuellement tous ces indicateurs sur une gaussienne, donnant les différentes mesures observées et leur fréquence :
III-B. Mode SINGLESHOTTIME et SAMPLETIME▲
Contrairement aux modes Throughput et AverageTime, le mode SingleShotTime ne mesure et n'effectue qu'une seule invocation par itération (l'attribut time de @Measurement est ignoré)

Ce mode permet notamment :
- de prendre des mesures à froid (unique itération sans « warmup ») ;
- de mesurer individuellement chacune des exécutions ;
- d'observer précisément l'évolution des temps, appel après appel.
SingleShotTime a l'avantage de fournir en résultat une distribution des mesures observées sur l'ensemble des itérations (percentiles). Il présente néanmoins deux inconvénients :
- le nombre de mesures prises est faible (une par itération), chaque mesure aberrante pèse donc lourd sur la moyenne calculée et la largeur de l'intervalle de confiance ;
- Sur un benchmark où les invocations sont très courtes, l'overhead dû à la capture des « temps système » peut être comparable à l'opération mesurée, donnant alors des résultats complètement biaisés.
Pour estomper ces défauts, il existe le mode SampleTime. Celui-ci ressemble à AverageTime : il exécute lui aussi en boucle les invocations dans une itération limitée dans le temps, mais mesure néanmoins les temps moyens sur des échantillons d'invocations à la place d'une moyenne globale sur l'itération. Grâce à cet échantillonnage, on obtient un nombre de mesures beaucoup plus grand, et une distribution des mesures sur une large population !
On pourra choisir la taille de nos échantillons avec l'attribut batchSize. De grands échantillons « dilueront » davantage cet overhead, et donneront ainsi plus de finesse dans les mesures ; nous en obtiendrons cependant un plus petit nombre. A contrario, avec de petits échantillons, nous obtiendrons beaucoup de mesures, mais davantage biaisées par l'overhead. Tout est donc question de dosage !
Voici un exemple de benchmark SampleTime, réalisant des échantillons de 100 exécutions par mesure :
2.
3.
4.
5.
6.
7.
8.
9.
@Benchmark
@BenchmarkMode(Mode.SampleTime)
@Measurement(iterations=10, time=1000, timeUnit=TimeUnit.MILLISECONDS, batchSize=100)
@OperationsPerInvocation(100) //conveniant way to display result “per operation”instead of “per batch”
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public void benchmarkSomething() {
// Here is a sample benchmark
// ...
}
Il nous donne les résultats suivants :
Result: 24,033 ±(99.9%) 0,756 ns/op [Average]
Statistics: (min, avg, max) = (22,000, 24,033, 2728,000), stdev = 25,221
Confidence interval (99.9%): [23,276, 24,789]
Samples, N = 12042
mean = 24,033 ±(99.9%) 0,756 ns/op
min = 22,000 ns/op
p( 0,0000) = 22,000 ns/op
p(50,0000) = 23,000 ns/op
p(90,0000) = 24,000 ns/op
p(95,0000) = 24,000 ns/op
p(99,0000) = 25,000 ns/op
p(99,9000) = 97,000 ns/op
p(99,9900) = 2198,659 ns/op
p(99,9990) = 2728,000 ns/op
p(99,9999) = 2728,000 ns/op
max = 2728,000 ns/op
# Run complete. Total time: 00:05:03
Benchmark Mode Cnt Score Error Units
benchmarkSomething sample 12042 24,033 ± 0,756 ns/opCe benchmark basé sur un échantillon de 12 042 mesures nous dit que :
- ce code a 99,9 % de chances de s'exécuter en 24,033 ns à 0,756 ns près (i.e. entre 23,276 et 24,789 ns) ;
- le meilleur temps réalisé est de 22 ns ;
- le temps médian est de 23 ns ;
- le pire temps réalisé est de 2728 ns ;
- 1 fois sur 100, ce code franchit la limite des 25 ns.
IV. Le mot de la fin▲
Pour réaliser un bon benchmark, il faut avant tout prendre des mesures correctes. Nous venons de voir plusieurs intérêts majeurs à l'utilisation de JMH pour réaliser nos benchmarks :
- la possibilité de reproduire « en laboratoire » des conditions comparables à celles de production : l'exécution de bytecode à chaud, grâce aux « warm up itérations », un contexte d'exécution multithreadé, ainsi que le tuning de la JVM, grâce aux forks ;
- la possibilité de tuner finement la précision de la prise de nos mesures sur des micro-opérations, afin d'éviter les pitfalls du microbenchmarking !
- la capacité à itérer et à fournir une population de mesures suffisamment grande pour avoir une approche « statistique » sur nos benchmarks, nous permettant de tirer des heuristiques, et de définir un SLA sur le code, tel qu'une latence maximale, ou encore une latence maximale avec une probabilité de dépassement.
V. Remerciements▲
Cet article a été publié avec l'aimable autorisation de la société SoatSoat.
Nous tenons à remercier Claude Leloup pour la relecture de cet article et milkoseck pour la mise au gabarit.