





I. Introduction▲

Le langage Java est le premier langage de programmation et, selon certaines sources, nous sommes 9 millions de développeurs Java dans le monde à l'utiliser quotidiennement. Mais combien d'entre nous connaissent les différents modes de compilation ? Les liens étroits qu'ils ont tissés avec les optimisations effectuées par la JVM ?
La majorité des développeurs savent que le JDK assure deux types de compilation :
- La première est de nature statique : elle est assurée par l'outil javac. Son rôle est de transformer le code Java bytecode ou code intermédiaire interprétable, donc en code exécutable sur tous types de plateformes disposant d'une JVM.
- La seconde est de nature dynamique : elle est assurée dans un premier niveau par l'interpréteur, puis par un composant appelé JIT, pour des niveaux de compilation plus avancés. Le bytecode généré par la compilation statique est ensuite transformé, en fonction d'un certain nombre de règles, en code machine optimisé. Les optimisations effectuées dépendent d'un certain nombre de règles et obéissent à des stratégies bien définies. Elles dépendent également des statistiques d'exécution. Autrement dit, les instructions fréquemment utilisées et qualifiées de Hot sont remplacées par du code compilé à la volée lors des appels suivants. Le code compilé ou recompilé peut subir une ou plusieurs optimisations. Plus amples sont les statistiques, plus agressives seront les optimisations appliquées.
Mais y a-t-il réellement uniquement deux compilations, ou est-ce la vulgarisation Java qui est à l'origine de cette idée reçue ?
Avant d'aller plus loin, commençons par le début et plongeons dans les fondations de l'écosystème Java.
II. Écosystème Java : Vue globale▲
Le bytecode est un code interprété. Il est généré par le compilateur javac et n'est pas compris par les processeurs comme c'est le cas du code machine. La transformation en code machine est possible grâce à une seconde compilation qui est de la responsabilité de la JVM. Cette compilation est spécifique à une plateforme donnée, car basée sur des librairies dépendantes de celle-ci.
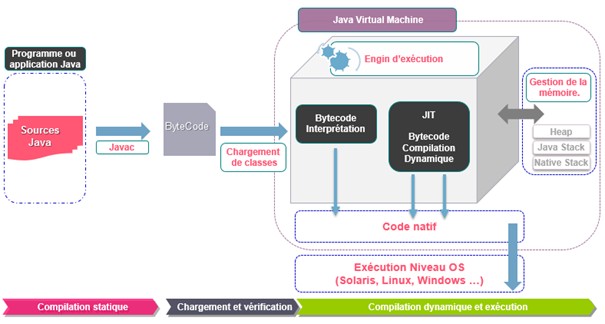
La figure 1 permet d'identifier et de présenter les éléments engagés depuis la compilation jusqu'à l'exécution, en passant par les décisions d'optimisation. Il me semble important de connaitre les éléments mis en scène, pour mieux en comprendre le rôle dans les mécanismes de compilation et/ou d'optimisation.
Dans ces premières versions, la JVM a été, à juste titre, décriée pour sa lenteur. Mais depuis, bien des améliorations ont été intégrées :
- Algorithme d'allocation/récupération de mémoire plus rapide et plus efficace (Parallèle GC, CMS, G1).
Heureusement, la majorité de ces capacités sont configurables et peuvent être adaptées aux applications Java pour répondre à différents besoins. Une phase de réglage (Tuning) est souvent nécessaire, car la configuration par défaut n'est pas toujours optimale. Mais une fois ces capacités bien configurées, elles permettent en général d'actionner des leviers permettant d'aboutir à des optimisations plus au moins agressives.
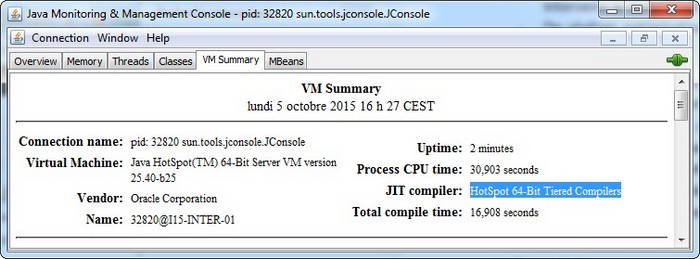
En effet, au sein de la JVM, en plus de l'interpréteur, deux compilateurs C1 et C2 coexistent. Le C1 est utilisé lorsqu'une faible empreinte mémoire et un démarrage rapide sont requis. Le C2 est plutôt utilisé pour les applications destinées à fonctionner durant de longues périodes, avec un besoin important en termes de rapidité d'exécution. L'un et l'autre sont obtenus respectivement en activant les options -client et -server au lancement de la JVM, et aboutissent, pour un même code Java, à un code machine différent en raison de la différence des techniques utilisées. Mais, depuis les derniers releases JDK 7, les applications Java peuvent bénéficier du meilleur des deux compilateurs. La technique porte le nom de Tiered compilation et permet à la fois :
- de s'assurer d'un lancement rapide et d'une faible consommation mémoire en faisant intervenir le compilateur C1 au démarrage d'une application ;
- de réaliser des optimisations agressives en cours d'exécution en s'appuyant plus sur le compilateur C2.
La différence entre les deux compilateurs est assez importante. Le C1 utilise peu ou pas les métadonnées d'exécution et, à ce titre, il consomme peu de mémoire et de CPU. Au contraire, le C2 a besoin d'analyser de grandes quantités d'informations issues des statistiques d'exécution, avant d'appliquer des optimisations agressives. Ceci lui vaut une certaine consommation en mémoire et CPU. Selon la documentation officielle, la combinaison des deux compilateurs, dans plusieurs cas de figure, offre de meilleures performances que le mode client ou server pris exclusivement, en raison d'un profilage plus performant des données d'exécution.
La figure ci-dessous montre que cette capacité est activée par défaut dans le JDK 8. Pour en bénéficier en JDK 7, surtout les dernières versions, il faut l'activer explicitement par le biais du flag -XX:+TieredCompilation.
III. Compilation et/ou optimisation ?▲
Jusque-là, nous avons recensé quatre compilateurs : Javac, C0, C1 et C2. Ceci peut suggérer la présence de quatre types de compilation basés chacun sur un ensemble de règles bien définies. Cependant, les choses ne sont pas aussi simples. Dans ce qui suit, nous apprendrons qu'il existe cinq niveaux, rien que pour la compilation dynamique, que certains de ces niveaux sont interconnectés. Nous verrons même les frontières s'estomper entre compilation et optimisation.
Ci-dessous les cinq niveaux de compilation dynamique :
- Compilation niveau 0 : elle est réalisée par l'interpréteur de bytecode. Ce dernier est simplement transformé en code machine compréhensible et exécutable par le processeur. Toutes les méthodes passent par ce niveau.
- Compilation niveau 1, 2 et 3 : sont assurées par le compilateur C1. Le niveau 1 occulte toutes les informations issues des statistiques d'exécution. On parle de full optimization with no profiling. Inversement, le niveau 3 s'appuie sur les informations recueillies par le profiler de la JVM et qui constituent les métadonnées des exécutions. Le niveau 2 est un niveau intermédiaire qui utilise deux compteurs. Le premier, appelé invocation counters permet de comptabiliser le nombre d'invocations d'une méthode. Le second, appelé backedge counters indique le nombre de fois que le pointeur d'exécution est revenu au début d'une boucle.
- Compilation niveau 4 : est assuré par le compilateur C2.
Toutes les opérations liées à la compilation dynamique se déroulent en arrière-plan. Plus elles sont poussées, plus elles occasionnent un coût en termes de consommation mémoire et de CPU, mais ce coût reste très négligeable par rapport aux gains apportés. Selon une publication d'Eva Andreasson, le gain est un code jusqu'à dix fois plus performant que celui produit par une compilation C0.
« […] the overhead is very small for the execution performance improvement gained — five or 10 times better performance than what you would get from pure interpretation (meaning, executing the bytecode as-is, without modification) ».
Java, nous le savons, est un langage dynamique qui permet de varier le comportement au moment de l'exécution. Autrement dit, les différents chemins d'exécution(s) ne peuvent être connus à l'avance et les différents niveaux de compilation existent pour permettre à la JVM de s'adapter à ce contexte d'exécution variant, et d'assurer un fonctionnement optimal. Plus le compilateur JIT (C1 et C2) dispose d'informations sur le contexte d'exécution, plus les optimisations seront adéquates et plus efficaces.
La JVM est devenue assez intelligente pour adapter, à la volée, les stratégies et les règles d'optimisation au contexte d'exécution. C'est ce qui lui vaut d'être qualifiée de JVM HotSpot. En monitorant toutes les exécutions, elle marque le code très sollicité. Elle le rend éligible à une compilation niveau 2, 3 ou 4. Effectivement, en mode Tiered Compilation, les frontières entre niveaux de compilation et entre niveaux d'optimisation peuvent bouger presque tout le temps. Elles sont fonction des données du profilage et des tailles des files de compilation. La compilation niveau 2 est, le plus souvent, utilisée en premier, car 30 % plus rapide que celle de niveau 3, elle-même plus rapide que la compilation niveau 4. Mais lorsque suffisamment de données d'exécutions sont disponibles (profilage niveau 0 et 3), pour atteindre de meilleures performances, le bytecode est compilé directement en niveau 3 ou 4. Les compilations de niveau 4 sont les plus poussées. Elles deviennent privilégiées dès lors que la file de compilation C2 n'est pas trop chargée et que les statistiques d'exécution récoltées après une compilation niveau 3 sont suffisantes.
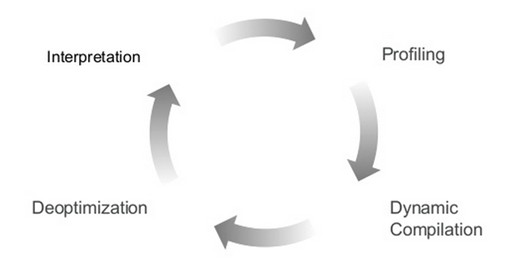
Le code machine obtenu est stocké en cache pour être réutilisé et gagner encore plus en performances. Dans cette optique, il est analysé et marqué non pertinent (no entrant) quand il le faut. On dit qu'il est dés-optimisé. Les instructions équivalentes repassent alors par la compilation niveau 0, pour ensuite être recompilées en niveau 2, 3 ou 4.
La JVM HotSpot jongle donc avec les niveaux de compilation pour offrir les meilleures performances. Toutes ces compilations/optimisations sont réalisées en parallèle de l'exécution de l'application, de sorte à n'induire presque aucun impact sur les performances globales sinon celui de les améliorer. Tirée de la littérature Java, la figure ci-dessous montre les différentes étapes que le bytecode peut être amené à suivre durant son cycle de vie :
La consultation des traces de compilation, activable grâce à l'option -XX:+PrintCompilation(-XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining pour plus de détails) permet de suivre ces transitions et d'en comprendre les raisons. Un outil existe et permet d'analyser ces logs de compilation. Il permet de prendre conscience des techniques d'optimisation utilisées et parfois de se les approprier pour écrire du code plus simple et plus performant. Il s'agit de JITWatch.
Le chapitre suivant présente et explique certaines de ces techniques. À titre d'exemple, certaines méthodes ne seront jamais compilées. Elles empêcheront donc une partie du code d'être compilée et optimisée. Nous rencontrons encore malheureusement des méthodes d'une centaine de lignes et plus, que dis-je, des fois des programmes entiers qui tiennent en une seule classe : connexion à la base de données, traçabilité, traitement métier, parsing, formatage des données en sortie, des boucles et des tests imbriqués à plusieurs niveaux. Tout est emmêlé, au point que même intelligente, la JVM ne peut presque rien y optimiser.
IV. Quelques tactiques et techniques d'optimisation▲
La JVM est capable de faire des optimisations en s'appuyant sur des techniques et stratégies de performance. Ces techniques sont organisées en plusieurs niveaux, les uns au-dessus des autres, de sorte que l'optimisateur puisse procéder à la technique du niveau supérieur une fois une technique donnée appliquée. Certaines de ces techniques sont agressives et s'appuient sur une collecte assez poussée des statistiques d'exécution. C'est le cas du Dead code Elimination. Comme son nom l'indique, le compilateur doit, de façon sûre et sécurisée, détecter des lignes de code qui ne seront jamais exécutées avant de les supprimer. C'est le cas, par exemple, de certains tests imbriqués. D'autres techniques, moins agressives et plus ou moins connues, gagnent à être explicitées. Ceci a participé à changer ma façon d'écrire du code, et très probablement, changera la vôtre.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
/**
* testlockElisionAndEscapAnalyse()
*
* @return String value
*/
private String testlockElisionAndEscapAnalyse() {
StringBuffer sBuffer = new StringBuffer();
Moteur oMoteur = new MoteurTypeF1();
sBuffer.append("Création moteur type F1");
Vehicule oVehicule = new Vehicule();
oVehicule.setNbPortes(4);
sBuffer.append("Création Vehicule 4 Portes");
oVehicule.setMoteur(oMoteur);
sBuffer.append("Vehicule : Ajout moteur Type F1");
return sBuffer.toString();
}
L'exemple ci-dessus est une construction pour illustrer une partie de l'analyse qu'effectue la JVM avant d'optimiser un code Java.
Nous le savons, la classe StringBuffer est une classe ThreadSafe dédiée à une utilisation en accès concurrent. Dans notre exemple, elle est utilisée en tant que variable locale. Elle ne sera donc jamais accédée par un thread concurrent. En effet, chaque thread crée ses propres variables au sein de la stack Java, dans un cadre d'exécution ou frame qui lui est propre. En se basant sur des analyses similaires ou plus complexes, la JVM va pouvoir procéder à une ou plusieurs optimisations dont certaines sont détaillées ci-dessous :
Lock Elision : nous savons que l'acquisition et la libération de verrous sont des opérations coûteuses et souvent à l'origine de contention et perte de performance, que les verrous sont requis à chaque fois que l'on fait appel à des instructions (méthode, bloc ou objet) synchronisées (Synchronized). Le code ci-dessus montre quatre appels de méthodes qui nécessitent, chacun, l'acquisition et la libération d'un verrou, ce qui revient très cher à l'exécution. Dans notre exemple, ceci est inutile, car l'objet sBuffer n'a pas besoin d'être synchronisé. L'optimisation qui consiste à supprimer les appels au moniteur de verrou à chaque fois que ceci est possible porte le nom de Lock Elision. Une technique assez similaire consiste à fusionner plusieurs blocs Synchronized en un seul, quand c'est possible. Il s'agit d'une autre optimisation qui porte le nom de Lock fusion.
Escape Analyse : cette technique, activée par défaut depuis le JDK6 u 23, permet au compilateur C2 de procéder à une optimisation assez agressive qui sollicite moins le processus d'allocation de mémoire et la pose de verrou (lock) associé et, du même coup, évite de faire travailler le Garbage Collector GC plus qu'il ne faille. L'analyse de l'échappement peut concerner différents cas :
- Objets stockés dans des champs static.
- Objets qui sont des attributs d'un autre objet lui-même sujet à l'échappement.
- Objets créés, retournés ou non à la fin de l'exécution d'une méthode.
- Objets créés à l'intérieur d'une boucle.
Plusieurs situations peuvent exister. Elles sont connues sous les noms de GlobalEscape, ArgEscape et NoEscape et sont, dans le cadre des optimisations, exploitées pour éviter l'allocation automatique de la mémoire au niveau du tas ou la Heap.
Le code ci-dessous montre la création de deux objets Vehicule et Moteur. Le second est référencé par le premier, mais les deux objets restent cantonnés dans le corps de la méthode. Ils ne sont donc visibles qu'au sein de la stack et de la frame d'exécution. On dit qu'ils ne sont pas sujets à l'échappement. Habituellement, les nouveaux objets sont créés dans la heap (young génération ou old génération si l'objet est volumineux), mais dans notre cas, l'escape analyse permet à la JVM HostSpot de shunter ce processus coûteux et de les créer seulement au niveau de la Stack. Ceci se traduit automatiquement par une consommation de mémoire moindre et participe à la réduction de la fragmentation de cette dernière.
Monomorphic dispatch : souvent, au sein d'une méthode, un seul chemin d'exécution est observé car prédominant. En cours d'exécution, le polymorphisme dû à l'héritage ou à la présence de différentes implémentations est soit inexistant, soit pas assez fort pour changer fréquemment le comportement de la méthode. Dans ces conditions, et en s'appuyant sur les statistiques d'exécution, la JVM peut décider de ne pas vérifier quelle implémentation ou surcharge de la méthode il faut invoquer. Ce type de contrôle appelé virtual method lookup est alors éliminé permettant un gain non négligeable en termes de performance. Selon Ben Evans, membre du comité exécutif Java SE/EE, le JIT est capable, dans ces conditions, de produire du code machine plus performant que celui produit par C++, car ce dernier ne peut pas éliminer aussi facilement ce coût de vérification.
Inlining : cette technique est parmi les plus connues et les plus utilisées par la compilation JIT. Elle consiste à remplacer, au sein de la méthode appelante, l'appel à une méthode par les instructions qui la constituent. Ceci permet de gagner du temps sur l'appel de méthode (pas de création de frame supplémentaire dans la Java stack , pas d'appel supplémentaire vers les pc register…). Par défaut, cette capacité est activée et toutes les méthodes de tailles inférieures à 35 bits sont inlinées. Ceci peut être reconfiguré via le paramètre JVM -XX:MaxInlineSize = 35. À titre d'exemple, les méthodes accesseurs (getX(), setX()) et les petites méthodes final sont tout le temps remplacées (inlined).
De façon générale, la compilation et le remplacement de l'appel d'une méthode, au sein de la JVM HotSpot dépend essentiellement des deux compteurs ci-dessous, et dont la somme constitue le flag CompileThreshold :
- Compteur d'invocation de la méthode connue sous le nom de method entry.
- Compteur pour le nombre de fois que le code d'une boucle est exécuté connu sous le nom de back edge loop.
Selon la documentation Oracle, la valeur par défaut de ce paramètre pour une JVM en mode client est de 1500. Il est de 10 000 pour une JVM fonctionnant en mode server. Certaines littératures proposent de paramétrer ce flag en réduisant sa valeur. Réduire la valeur de ce dernier conduit à une compilation plus précoce et inversement. C'est ce qui est fait discrètement lorsque la Tiered Compilation est activée.
En pratique, il est possible que certaines méthodes ne soient jamais compilées même si elles sont exécutées fréquemment sur de longues durées. Dans l'absolu, ceci n'est pas grave, mais ce n'est pas du tout le cas lorsque ces méthodes sont critiques pour un programme. L'explication vient du fait qu'elles sont trop volumineuses et excédent la barrière fixée par le flag XX:FreqInlineSize=325. L'utilisation d'outil comme JITWatch, permet d'aller beaucoup plus loin que le simple contrôle CheckStyle : MethodLengthCheck. Elle permet non seulement de détecter ces méthodes, mais d'en faire des candidates pour le refactoring, aboutissant ainsi à un gain en termes de performances. L'outil permet également de recenser les méthodes qui sont dés-optimisées, car elles englobent différents chemins d'exécution. Elles aussi peuvent devenir candidates au refactoring.
V. Conclusion▲
Dans cet article, nous avons découvert qu'il y avait plusieurs compilateurs, que les différences principales entre compilation statique et dynamique étaient le déroulement de cette dernière en parallèle à l'exécution normale, et que son but était de passer de la simple génération de code machine à la génération de code machine optimisé et performant.
Nous avons aussi commencé à esquisser quelques techniques d'optimisation utilisées par la JVM.
VI. Remerciements ▲
Cet article a été publié avec l'aimable autorisation de la société Soat.
Nous tenons à remercier f-leb pour la relecture orthographique, et Malick SECK pour la mise au gabarit.