




I. Les concepts▲
Apache Cassandra est un système permettant de gérer une grande quantité de données de manière distribuée. Ces dernières peuvent être structurées, semi-structurées ou pas structurées du tout.

Cassandra a été conçu pour être hautement scalable sur un grand nombre de serveurs tout en ne présentant pas de Single Point Of Failure (SPOF).
Cassandra fournit un schéma de données dynamique afin d'offrir un maximum de flexibilité et de performance.
Mais pour bien comprendre cet outil, il faut tout d'abord bien assimiler le vocabulaire de base.
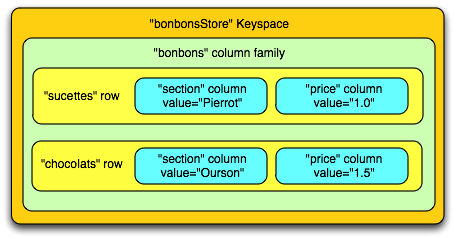
- Keyspace : c'est l'équivalent d'une database dans le monde des bases de données relationnelles. À noter qu'il est possible d'avoir plusieurs « Keyspaces » sur un même serveur.
- Colonne (Column) : une colonne est composée d'un nom, d'une valeur et d'un timestamp (instant de création).
- Ligne (Row) : les colonnes sont regroupées en Rows. Une Row est représentée par une clé et une valeur. Il existe deux types de rows : les « wide row » permettant de stocker énormément de données, avec beaucoup de colonnes et les « skinny row » permettant de stocker peu de données.
- Une famille de colonnes (Column family) : c'est l'objet principal de données et peut être assimilé à une table dans le monde des bases de données relationnelles. Toutes les rows sont regroupées dans les column family.
II. Architecture de Cassandra▲
Une instance Cassandra est une collection de nœuds indépendants qui sont configurés ensemble pour former un cluster.
Dans un cluster, tous les nœuds sont égaux, ce qui signifie qu'il n'y a pas de nœud maître ou un processus centralisant leur gestion.
En fait, Cassandra utilise un protocole appelé Gossip afin de découvrir la localisation et les informations sur l'état des autres nœuds du cluster. Le protocole Gossip est un protocole de communication de type « peer-to-peer » dans lequel les nœuds échangent périodiquement des informations sur leur état mais également sur ce qu'ils savent des autres nœuds.
Pour être plus précis, le processus s'exécute toutes les secondes afin d'échanger les messages avec au plus trois autres nœuds du cluster. De plus, une version est associée à ces messages afin de permettre d'écraser les informations plus anciennes.
Ainsi, quand un nœud démarre, il regarde dans son fichier de configuration les points de ralliement (SEED) qui devront au moins être contactés une fois.
Cependant, afin d'éviter un partitionnement, tous les nœuds du cluster doivent disposer de la même liste de nœuds dans leur fichier de configuration.
La détection des échecs est une méthode pour déterminer localement si un autre nœud est accessible ou pas. En outre, les informations récoltées par ce mécanisme permettent à Cassandra d'éviter d'émettre des requêtes aux nœuds qui ne sont plus accessibles.
En fait, ce mécanisme fonctionne sur le principe de heartbeat soit de manière directe (en récoltant les informations directement des nœuds) soit de manière indirecte (en récoltant les informations par l'intermédiaire de la connaissance des autres nœuds).
Lorsqu'un nœud est déclaré comme inaccessible, les autres nœuds stockent les messages susceptibles d'avoir été manqués par ce nœud. Cependant, il peut arriver qu'entre le moment où le nœud devient inaccessible et le moment où sa perte est détectée, un laps de temps s'écoule et qu'ainsi, les réplicas ne soient pas conservés. En outre, si le nœud vient à être indisponible pendant une période trop importante (par défaut, une heure), alors les messages ne sont plus stockés. C'est pour cette raison qu'il est conseillé d'exécuter régulièrement l'outil de réparation des données (NODE_REPAIR).
III. Partitionnement des données avec Cassandra▲
Il est possible de configurer le partitionnement pour une famille de colonnes en précisant que l'on veut que cela soit géré avec une stratégie de type Ordered Partitioners.
Ce mode peut, en effet, avoir un intérêt si l'on souhaite récupérer une plage de lignes comprises entre deux valeurs (chose qui n'est pas possible si le hash MD5 des clés des lignes est utilisé).
Cependant, il est conseillé d'utiliser plutôt une deuxième clé d'indexation positionnée sur la colonne contenant les informations voulues. En effet, utiliser la stratégie Ordered Partitionners a les conséquences suivantes :
- l'écriture séquentielle peut entraîner des hotspots : si l'application tente d'écrire ou de mettre à jour un ensemble séquentiel de lignes, alors l'écriture ne sera pas distribuée dans le cluster ;
- un overhead accru pour l'administration du load balancer dans le cluster : les administrateurs doivent calculer manuellement les plages de jetons afin de les répartir dans le cluster ;
- répartition inégale de charge pour des familles de colonnes multiples.
IV. La répartition des données avec Cassandra▲
La réplication est le processus permettant de stocker des copies des données sur de multiples nœuds afin de permettre leur fiabilité et la tolérance à la panne. Quand un keyspace est créé dans Cassandra, il lui est affecté la stratégie de distribution des réplicas, c'est-à-dire le nombre de réplicas et la manière dont ils sont répliqués dans le cluster.
La stratégie de réplication repose sur la configuration du cluster Snitch afin de déterminer la localisation physique des nœuds ainsi que leur proximité par rapport aux autres.
Il est souvent fait référence au facteur de réplication (replication factor que nous nommerons RF par la suite) pour parler du nombre total de réplicas dans le cluster.
Aussi :
- un facteur de réplication de 1 signifie qu'il n'y a qu'une seule copie de chaque ligne ;.
- un facteur de réplication de 2 signifie qu'il existe deux copies de chaque ligne ;
- ...
Tous les réplicas possèdent la même importance : il n'y a pas de réplicas principaux ou maîtres du point de vue de la lecture et de l'écriture.
Ainsi, la règle générale est que le facteur de réplication ne doit pas être supérieur au nombre de nœuds dans le cluster. Cependant, il est possible d'augmenter le facteur de réplication puis d'ajouter le nombre de nœuds désirés à postériori. À noter toutefois que lorsque le facteur de réplication est supérieur au nombre de nœuds, alors les écritures ne sont plus prises en compte tandis que l'opération de lecture reste maintenue tant que le degré de consistance est respecté.
Concernant les stratégies de distribution des réplicas, cela permet de jouer sur la façon dont les réplicas sont répartis dans le cluster pour un keyspace. Cette stratégie est à renseigner lors de la création de la keyspace.
De plus, il est possible de configurer la manière dont les nœuds sont groupés ensemble dans la topology du réseau global. Cet élément de configuration correspond au snitch et est associé au cluster. Cassandra utilise alors cette information pour router les requêtes entre les nœuds.
V. Cassandra du point de vue de l'application Client▲
Tous les nœuds de Cassandra sont égaux. Ainsi, une demande de lecture ou d'écrire peut interroger indifféremment n'importe quel nœud du cluster. Quand un client se connecte à un nœud et demande une opération d'écriture ou de lecture, le nœud courant sert de coordinateur du point de vue du client.
Le travail du coordinateur est de se comporter comme un proxy entre le client de l'application et les nœuds qui possèdent la donnée. C'est lui qui a la charge de déterminer quels nœuds de l'anneau devront recevoir la requête.
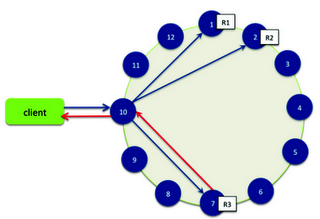
Concernant les requêtes d'écriture, le coordinateur émet la requête à tous les réplicas qui possèdent la ligne à modifier. Aussi longtemps qu'ils sont disponibles, ils reçoivent les demandes d'écriture quel que soit le niveau de consistance demandé par le client. Le niveau de « consistance » d'écriture détermine le nombre de nœuds qui doivent acquitter l'écriture afin de considérer l'écriture comme ayant réussi.
Dans le cas où il existe plusieurs data center deployments, Cassandra optimise les performances d'écriture en choisissant un nœud coordinateur dans chaque data center distant afin de traiter les requêtes des réplicas dans le data center. Le nœud coordinateur contacté par l'application cliente n'a alors qu'à transmettre les requêtes d'écriture à un seul nœud de chaque data center distant.
Si le niveau de consistance choisi est ONE ou LOCAL_QUORUM, alors seuls les nœuds du même « data center » que le nœud coordinateur doivent acquitter l'écriture.
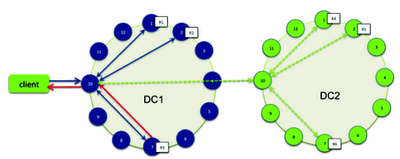
Concernant la lecture, il y a deux types de requêtes de lecture qu'un coordinateur peut émettre à un réplica :
- une requête de lecture directe. Dans ce cas, le nombre de réplicas contactés par une demande de lecture directe est déterminé par le niveau de consistance spécifié par le client ;
- une requête de réparation de lecture en tâche de fond. Dans ce cas, elle est envoyée à tous les réplicas additionnels qui n'ont pas reçu de requête directe. Ce type de requête permet de vérifier que la ligne est consistante par rapport aux autres réplicas.
Ainsi, dans un premier temps, le coordinateur contacte les réplicas en fonction du niveau de consistance qui a été spécifié. Ces réplicas sont choisis en fonction de leur capacité à répondre rapidement. Ces derniers répondent avec la donnée demandée et, s'il existe plusieurs réponses, elles sont comparées en mémoire afin de vérifier leur consistance.
Si ce n'est pas le cas, alors c'est le réplica qui est le plus récent (en se basant sur le timestamp) qui est utilisé par le coordinateur pour répondre au client.
En outre, afin de s'assurer que tous les réplicas ont la version la plus récente, le coordinateur les contacte en tâche de fond et compare la donnée de tous les réplicas restants qui possèdent la ligne. Il demande ensuite, éventuellement, une opération d'écriture afin de mettre à jour la donnée. C'est cette opération qui est appelée read repair et qui peut être configurée par famille de colonnes (par défaut, elle est désactivée).
VI. Le modèle de données de Cassandra▲
Le modèle de données de Cassandra s'appuie sur un schéma dynamique, avec un modèle de données orienté colonne.
Cela signifie que, contrairement à une base de données relationnelle, il n'est pas nécessaire de modéliser toutes les colonnes puisqu'une ligne n'a, potentiellement, pas le même ensemble de colonnes.
Les colonnes et leurs métadonnées peuvent être ajoutées par l'application lorsque cela s'avère nécessaire.
En fait, le modèle de données de Cassandra a été pensé pour répondre à des problématiques de données distribuées et diffère complètement d'un modèle classique de base de données relationnelle où les données sont stockées dans des tables qui sont, dans la plupart des cas, en relation entre elles. En outre, dans un modèle relationnel, les données sont généralement normalisées afin d'éviter la redondance et des jointures sont faites entre les tables sur des clés communes afin de satisfaire les requêtes.
Dans Cassandra, le Keyspace est le conteneur des données de l'application (un peu comme une database ou un schéma pour une base de données relationnelle). Dans ces keyspaces se trouvent une ou plusieurs familles de colonnes (qui correspondent aux tables en base de données relationnelle).
Ces familles de colonnes contiennent des colonnes ainsi qu'un ensemble de colonnes connexes qui sont identifiées par une clé de ligne. En outre, chaque ligne d'une famille de colonnes ne dispose pas nécessairement des mêmes colonnes qu'une autre ligne.
Enfin, Cassandra n'impose pas de relations entre les familles de colonnes au sens base de données relationnelle : il n'y a pas de clés étrangères et les jointures entre familles de colonnes ne sont pas supportées.
Ainsi, en simplifiant chaque famille de données dispose de son ensemble de colonnes qui sont destinées à être consultées ensemble pour satisfaire les requêtes spécifiques à l'application.
En outre, les familles de colonnes peuvent définir les métadonnées des colonnes mais pour une colonne donnée correspondant à une ligne, cela est à la charge de l'application. De plus, chaque ligne peut disposer d'un ensemble de colonnes différentes.
Par contre, bien que les familles de colonnes puissent être flexibles, dans la pratique, il est conseillé d'y associer une sorte de schéma (à une famille de colonnes, il est préférable de n'y mettre qu'un même type de données).
En fait, il y a deux types de familles de colonnes :
- les familles de colonnes statiques : elles utilisent un ensemble statique de noms de colonne et sont très similaires à une table d'une base de données relationnelle même si toutes les colonnes n'ont pas à être obligatoirement renseignées. À noter qu'en général, les métadonnées des colonnes sont définies, dans ce cas, pour chaque colonne ;
- les familles de colonnes dynamiques : elles permettent, par exemple, de précalculer un ensemble de résultats et de les stocker dans une même ligne afin de pouvoir y accéder plus tard. Chaque ligne correspond donc à un snapshot de données correspondant à une requête donnée. À noter que, pour une famille de colonnes dynamiques, plutôt que d'avoir des métadonnées pour chaque colonne, le type des informations par colonnes (tel que le comparateur et les validateurs) est défini par l'application lorsque la donnée est insérée.
Pour toutes les familles de colonnes, chaque ligne est identifiée de manière unique par sa clé (un peu comme la notion de clé primaire pour les bases de données relationnelles). Une famille de colonnes est, quant à elle, toujours partitionnée par ses clés de ligne qui sont, implicitement, indexées.
En fait, dans Cassandra, une colonne est le plus petit incrément de données. Elle est modélisée par un tuple qui contient le nom, la valeur et un timestamp. Ce timestamp est utilisé par Cassandra pour déterminer la mise à jour la plus récente dans la colonne (et, dans ce cas, c'est la plus récente qui est prioritaire lors d'une requête).

Une colonne doit avoir un nom qui peut être un label statique (comme "nom" ou "email") ou peut être mis dynamiquement lorsque la colonne est créée par l'application.
Les colonnes peuvent être indexées par leur nom (en utilisant un second index).
Cependant, une limitation de l'indexation des colonnes est le non-support des requêtes qui nécessite un ordonnancement comme cela peut être le cas avec une collection de données de temps. En effet, dans ce cas, un second index sur la colonne de timestamp ne serait pas suffisant car il n'est pas possible d'avoir la main sur l'ordonnancement de la colonne avec un index secondaire. Pour pallier ce manque, il est toujours possible de maintenir manuellement une famille de colonnes qui ferait office d'index.
Il est à noter qu'il n'est pas obligatoire pour une colonne d'avoir une valeur puisque, parfois, le nom de cette dernière lui suffit à elle-même.
En plus des colonnes dites "classiques", Cassandra offre trois autres types de colonnes :
- Expiring Columns qui disposent d'un TTL (Time To Live) ;
- Counter Columns qui permettent de stocker un compteur
-
 Super Columns qui permettent de gérer une métacolonne pouvant contenir d'autres colonnes. (Attention, ne sera bientôt plus supporté.)
Super Columns qui permettent de gérer une métacolonne pouvant contenir d'autres colonnes. (Attention, ne sera bientôt plus supporté.)
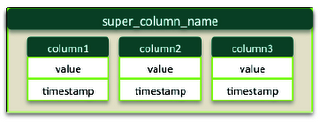
Concernant, le type de données exploitables par Cassandra, il existe deux notions :
- le validator qui est le type de données pour la valeur d'une colonne (ou la clé d'une ligne) ;
- le comparator qui est le type de données pour le nom d'une colonne.
En fait, il est possible de définir un type de données lors de la création d'une famille de colonnes et que son schéma est précisé (cf. les familles de colonnes statiques). Cassandra stocke alors, par défaut, le nom et les valeurs des colonnes en tableau d'hexadécimal (BytesType).
Ci-dessous, la liste des valeurs possibles pour les validator et comparator (sauf pour le type CounterColumnType qui ne peut être utilisé que comme valeur de colonne) :
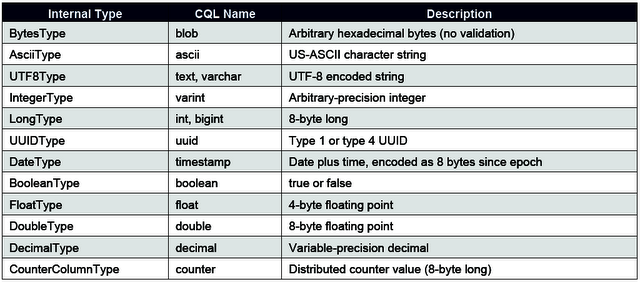
Plus précisément sur les validator, pour toutes les familles de colonnes, il est conseillé de définir un validator par défaut pour une clé de ligne (qui peut être modifié ou ajouté au besoin). Dans ce cas, une vérification est effectuée lors de l'insertion ou la mise à jour de données.
Concernant le comparator, il est à noter que, dans une ligne, les colonnes sont toujours stockées de manière ordonnée par rapport au nom des colonnes. Le comparator précise le type de données pour le nom d'une colonne mais ne peut être modifié.
VII. L'indexation dans Cassandra▲
Un index est une structure de données qui permet un accès rapide ainsi qu'une recherche de données par rapport à un ensemble de critères donnés.
Dans les bases de données classiques, une clé primaire est une clé unique utilisée pour identifier chaque ligne d'une table. Cela permet, comme tous les index, d'accélérer l'accès aux données dans une table. La clé primaire garantit également l'unicité et peut également se charger de l'ordonnancement des données.
Dans Cassandra, l'index primaire d'une famille de colonnes correspond à l'index de ses clés de ligne. Puisque chaque nœud connait la plage de ses clés par nœuds gérés, les requêtes sur les lignes sont plus aisées à localiser en scannant l'index des lignes sur un nœud donné.
Avec un partitionnement aléatoire des clés de ligne (qui est la configuration par défaut), les clés de ligne sont partitionnées par le hash MD5 et ne peuvent donc pas gérer l'ordonnancement (au sens ordre des données). Il est à noter qu'utiliser un partitionnement ordonné n'est pas conseillé puisque cela implique une maintenance accrue pour la distribution des données sur les nœuds.
Cassandra propose également un index secondaire qui se fait sur la valeur des colonnes. Il permet d'effectuer des opérations disposant de prédicats d'égalité (par exemple, where column x = value y). Ainsi, les requêtes sur des valeurs indexées peuvent appliquer une sorte de filtres.
VIII. L'accès aux données dans Cassandra▲
VIII-A. L'écriture▲
Cassandra est optimisé pour permettre une écriture rapide et hautement disponible des données avec un débit élevé. Pour ce faire, les données sont écrites dans un premier temps dans un journal de commit (pour s'assurer de la durabilité), puis dans une structure en mémoire appelée la Memtable. Une écriture est considérée comme ayant réussi si les deux actions précédentes ont réussi. Cela permet d'avoir peu d'entrées/sorties disque au moment de l'écriture. Ainsi, les données sont mises en mémoire et périodiquement écrites sur le disque dans une structure appelée une SSTable (pour Sorted String Table).
Les Memtables et SSTables sont maintenues par famille de colonnes : les Memtables sont organisées de manière ordonnée par clé de ligne et sont flushées dans les SSTables de manière séquentielle.
À noter également que les SSTables sont immuables, ce qui signifie qu'une ligne peut, typiquement, être stockée dans plusieurs fichiers de SSTables. Ainsi, pour répondre à une requête de lecture, il est nécessaire de combiner toutes les SSTables se trouvant sur le disque pour trouver la valeur d'une ligne. Pour optimiser ce processus, Cassandra utilise une structure en mémoire appelée Bloom Filter : chaque SSTable dispose de son propre Bloom Filter qui est utilisé pour vérifier si la clé d'une ligne existe lors d'une requête.
De plus, en tâche de fond, Cassandra merge périodiquement les SSTables ensemble dans une SSTable d'une taille supérieure. Ce processus est appelé Compaction. Plus précisément, il regroupe les fragments de lignes ensemble, supprime les colonnes qui ont été marquées comme devant être supprimées et reconstruit les index primaires et secondaires. Bien sûr, ce processus a des impacts sur les disk I/O.
Contrairement aux bases de données relationnelles classiques, Cassandra n'offre pas des transactions dites ACID : il n'y a pas de locks ou de dépendances transactionnelles lors d'une mise à jour concurrente de multiples lignes ou de familles de colonnes.
Pour rappel, ACID est l'acronyme de :
- Atomic : tout ce qu'il y a dans une transaction doit être réussi ou sinon un rollback est effectué ;
- Consistent : une transaction ne peut pas laisser la base de données dans un état incohérent ;
- Isolated : les transactions ne peuvent pas interagir les unes avec les autres ;
- Durable : les transactions effectuées persistent même après une défaillance du serveur.
Pour sa part, Cassandra ne traite que les concepts d'isolation et d'atomicité. En fait, pour être plus précis, une écriture est atomique au niveau des lignes (i.e. l'insertion ou la mise à jour des colonnes d'une ligne donnée est traitée comme une écriture unique). Ainsi, Cassandra ne supporte pas les transactions dans le sens de mise à jour de lignes multiples. De même, il n'y a pas de rollback lorsque l'écriture réussit sur un nœud mais échoue sur les autres (dans ce cas, il n'est possible d'avoir qu'un rapport d'erreur mais pas de rollback).
Cassandra utilise les timestamps pour déterminer la mise à jour la plus récente d'une colonne ; ce timestamp étant fourni par l'application cliente. Ainsi, la donnée avec le dernier timestamp est toujours celle qui prévaut lors d'une requête. C'est pour cela que, si de multiples clients mettent à jour la même donnée de manière concurrente, alors c'est la donnée la plus récente qui sera persistée.
Du côté de la durabilité, toutes les écritures sur un réplica sont enregistrées à la fois en mémoire et dans le journal de commit avant que l'acquittement ne soit émis. Si un échec se produit avant l'écriture sur disque, alors le journal de commit est rejoué du début afin de récupérer les données qui n'ont pas encore été écrites.
VIII-B. L'insertion et la mise à jour▲
Plusieurs colonnes peuvent être insérées en même temps. Ainsi, lorsque des colonnes sont insérées ou mises à jour dans une famille de colonnes, l'application cliente précise la clé de ligne pour identifier l'enregistrement à mettre à jour. La clé de la ligne peut donc être vue comme une clé primaire puisqu'elle doit être unique pour chaque ligne dans une famille de colonnes donnée. Cependant, à la différence d'une clé primaire, il est possible d'insérer des données à une clé primaire déjà présente, mais dans ce cas, Cassandra répondra comme une mise à jour (si elle n'existe pas, elle sera créée).
De plus, les colonnes sont écrasées si le timestamp d'une autre version de colonne est plus récent. Il est, cependant, à noter que le timestamp est fourni par le client. Aussi, ces derniers doivent disposer d'une horloge synchronisée par NTP (Network Time Protocol).
VIII-C. La suppression▲
Lorsqu'une ligne ou une colonne est supprimée dans Cassandra, il est important de comprendre les points ci-dessous :
- la suppression de la donnée du disque n'est pas immédiate (pour rappel, une donnée insérée est écrite dans la SSTable qui se trouve sur le disque). En effet, la SSTable étant immuable, un marqueur appelé tombstone est écrit pour renseigner le nouveau statut de la colonne. Les colonnes ainsi marquées persistent pendant un certain laps de temps configurable puis sont réellement supprimées lors du processus decompaction ;
- une colonne supprimée peut réapparaitre si la routine de réparation de nœud n'est pas exécutée. En effet, marquer une colonne d'un tombstone implique qu'un réplica qui était dans un état non atteignable lors de la suppression ne recevra l'information que lorsqu'il sera de nouveau dans un état joignable. Cependant, si un nœud est injoignable plus longtemps que le temps configuré de conservation des tombstones, alors le nœud peut complètement manquer la suppression et répliquer les données supprimées lors de son retour dans le cluster ;
- la clé de ligne pour une ligne supprimée apparait toujours dans la plage de résultats d'une requête. En effet, quand une ligne est supprimée dans Cassandra, ses colonnes correspondantes sont marquées par un tombstone. Ainsi, tant que les données marquées par un tombstone ne sont pas réellement supprimées par le processus de compaction, la ligne reste vide (i.e. sans colonne associée).
VIII-D. La lecture▲
Pour rappel, lorsqu'une requête de lecture d'une ligne est reçue par un nœud, la ligne doit être combinée de toutes les SSTables du nœud qui contiennent les colonnes de la ligne en question ainsi que de toutes les Memtables. Pour optimiser ce processus, Cassandra utilise une structure en mémoire appelée les bloom filter : chaque SSTable dispose d'un bloom filter associé qui est utilisé pour vérifier s'il existe des données dans la ligne avant de faire une recherche (et ainsi de faire des entrées/sorties disque).
VIII-E. La consistance des données dans Cassandra▲
Lorsqu'il est fait question de consistance dans Cassandra, cela s'applique à la façon dont est maintenue la cohérence des données et comment les lignes de données sont synchronisées entre tous les réplicas.
Cassandra étend le concept de cohérence éventuelle en offrant une consistance réglable.
Ainsi, pour toute opération de lecture ou d'écriture, l'application cliente peut décider du degré de consistance que doit avoir la requête. En plus de cela, Cassandra dispose d'un mécanisme de réparation afin de s'assurer de la consistance des données entre les différents réplicas.
VIII-F. Consistance réglable pour les requêtes clientes▲
Le niveau de consistance dans Cassandra peut être associé à n'importe quelle requête de lecture ou d'écriture. Cela permet aux développeurs de l'application de trouver le juste milieu entre le temps d'exécution de leurs requêtes et la consistance qu'ils souhaitent avoir sur les résultats obtenus.
Lors d'une écriture, le niveau de consistance précise sur combien de réplicas doit être écrite la donnée avant d'être acquitté du succès de l'opération.
Les niveaux de consistance disponibles sont les suivants :

En fait, pour être plus précis, un quorum est calculé de la manière ci-dessous :

Ainsi, par exemple, si le facteur de réplication est de 3, alors le quorum est de 2 (c'est-à-dire que l'on ne tolère qu'un seul réplica soit indisponible).
De même, si le facteur de réplication est de 6, alors le quorum est de 4 (c'est-à-dire que deux réplicas peuvent être indisponibles).
Lors d'une lecture, le niveau de consistance spécifie combien de réplicas doivent répondre avant que le résultat ne soit fourni au client.
Cassandra contacte le nombre de réplicas indiqué afin d'obtenir la donnée la plus récente (en se basant sur le timestamp).
Les niveaux de consistance disponibles sont les suivants :

Le niveau quorum est calculé de la même manière que pour l'écriture.
De même, pour un facteur de réplication de 6, le quorum est de 4 (c'est-à-dire que 2 réplicas peuvent être indisponibles).
Concernant le choix du niveau de consistance sur l'écriture et la lecture, cela dépend, bien sûr, des besoins mais impacte fortement le comportement de Cassandra.
Ainsi, si la latence est une priorité, un niveau de consistance à ONE peut être envisageable. Bien sûr, dans ce cas, il y a une forte probabilité que les données lues ne soient pas cohérentes.
À l'inverse, si c'est l'écriture qui importe, alors une consistance à un niveau ANY peut répondre au besoin. Dans ce cas, ce sont les données lues qui risquent de ne pas être consistantes.
À noter que si c'est la consistance qui est importante (c'est-à-dire que les données lues sont les plus proches possible de ce qui a été écrit), alors la formule suivante peut être appliquée :
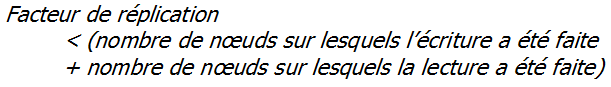
IX. Conclusion▲
Vous l'aurez compris, Cassandra est un formidable outil doté d'une architecture passionnante et pouvant servir de référence en architecture logicielle.
À utiliser, vous l'aurez compris, avec modération pour des besoins exceptionnels dans vos applications. Tout choix d'architecture logicielle est une question de compromis.
X. Remerciements▲
Cette rétrospective de Devoxx France 2012 a été réalisée par Khanh Tuong Maudoux et François Ostyn, consultants Soat et reporters Developpez.com pour Devoxx France 2012.
Cet article a été publié avec l'aimable autorisation de la société SoatSoat.
Nous tenons à remercier ClaudeLELOUP pour sa relecture orthographique attentive de cet article et Mickael Baron pour la mise au gabarit.